
THE BLOG
The Office That Earns Its Rent
Buildings that can prove they deliver for occupiers

Smart buildings optimise. Causal buildings prove. The next office advantage is not a smarter thermostat or a slicker tenant app: it is a building engineered to prove, causally, what it does for the people and businesses inside it. The capital that could build it is not yet pointed at it, and the players racing into AI cannot own it, which is exactly why it is still a moat.
There is a debate running through commercial real estate about how to wire up a building’s data: sensors or business systems, one cleaned central store or a layer over what you already have. I have sat with it for a while and come to think it is the wrong argument, or at best a second-order one. In a market culling offices that cannot justify their rent, the question is not how you plumb the data. It is what you are trying to build with it.
The short version. The industry is arguing about data architecture when it should be asking what the data is for. A building set up properly for AI can answer three escalating questions: what is happening, why it is happening and what happens if I intervene, and what to do about it. The hard part is causation, and it is half-solved already: physics-based control handles the engineering side and is now buyable; the commercial side, whether the building causally drives rent and retention, is the prize, and it is a portfolio capability that institutions are uniquely placed to own. Incumbents do not build it because their incentives forbid it, and even the new AI consortia arming the industry leave it untouched. The model is a commodity. The causal substrate is the moat, and it is most valuable retrofitted into the ageing offices fighting for their lives.
Two years ago I argued that real estate’s future was to become a Maven: not a passive provider of space but an active facilitator of human success, judged on outcomes: productivity, wellbeing, the things people actually come to an office for. I stand by every word. But a Maven makes a promise it has had no way to keep. It claims to improve the people inside it; ask it to prove that, causally, to a tenant weighing a renewal or an investor setting a price, and it goes quiet. The causal building is how the Maven keeps its promise.
THE ARGUMENT ABOUT PLUMBING
The current debate is narrower, and a long way from that promise. Strip away the jargon and it is an argument about plumbing. One camp wants a building’s intelligence to come from its own sensors and equipment: the data at the ‘edge’. Another wants it wired together from the business systems you already run, the leasing and accounting and management software: the ‘APIs at the core’. Beneath that sits a second quarrel about whether you haul everything into one clean central store or leave it where it lives and build over the top.
Plumbing matters. But choosing a side in it does not, by itself, give you intelligence, and it is downstream of a better question: what would a building look like if it were set up, deliberately, to produce causal evidence about what it does to the people inside it, and to act on that evidence?
Call it the causal building. Not a ‘smart’ building, the connected-automated-efficient-pleasant thing the industry has promised for thirty years and the best new towers now deliver. A building that works as an evidence engine. It knows not only what is happening and what will happen, but why, and what changes if it acts. And it can prove it to an audit committee.
THREE QUESTIONS A BUILDING SHOULD ANSWER
There are three kinds of AI doing the rounds, and they are not interchangeable. They make escalating demands, and a building set up properly answers all three:
Analytical AI answers what is happening, and what will happen. Prediction, anomaly detection, the energy curve. This is the commodity layer.
Causal AI answers why it is happening, and what happens if I change something.Explanation and counterfactual. This is where the money is.
Generative AI answers given all that, what should we do, and can you do it. The interface, and the hands.
Almost every ‘smart building’ on the market answers only the first. It senses, predicts and optimises beautifully, and stops there. The value, and the difficulty, climbs with each step. Causation is the one the industry has skipped.
THE CAUSAL PROBLEM IS HALF-SOLVED
Here is the good news, because the causal question sounds impossibly demanding and is not. It splits in two.
The engineering half, energy and comfort and the behaviour of the plant, is governed by physics, and a physics model is already a causal model. It knows that opening the damper moves the air without having to run an experiment to find out. Correlation has to be taught; physics comes knowing. Troy Harvey’s PassiveLogic is the clearest example: a physics-based digital twin that runs autonomous control at the edge and infers what it cannot directly measure. You can buy a version of this, or build a generic one with decades-old model-predictive control. Either way you specify engineering causality. You do not invent it.
The commercial half is the prize, and no physics will help you. Does comfort causally lift renewal? Does a floor’s configuration causally raise the tenant’s own productivity, and so their willingness to pay? These are questions of cause and effect in human behaviour, and they need experiments: matched floors, staggered rollouts, the boring discipline of logging every intervention and its result. The methods are standard econometrics. What is scarce is the will to use them.
In practice it looks like product experimentation pointed at space. One floor runs an altered lighting or thermal regime while a matched floor holds steady; an amenity change goes to one building and not its twin; every intervention is logged against the things that actually move money, renewal risk, utilisation, complaints, helpdesk tickets, sentiment. The aim is not laboratory perfection. It is disciplined comparison, repeated across enough assets to learn faster than the market.
A single building cannot run good experiments; a portfolio can. Scale, which usually buys you nothing but procurement leverage, here buys a causal-learning advantage no rival can copy without the same fleet. Better still, the autonomous control that delivers the engineering half is the very instrument that makes the commercial half feasible: a building that can hold a variable exactly, or vary it cleanly across two floors, is a controllable experiment. The thing everyone wants for energy is the thing that lets you finally answer the questions that move NOI.
There is a red line, and it is not optional. This works at the level of the floor, the cohort, the tenant and the portfolio. It does not work, and must never work, at the level of the named employee. The moment the causal building becomes workplace surveillance dressed as building intelligence it is unlettable, and rightly so. The trust architecture matters as much as the data architecture: consent, aggregation, governance.
WHY JP MORGAN STOPPED SHORT
If this is so valuable, why is it not being done? The answer is structural.
The brokers are disqualified by their own model. JLL has Hank, a genuinely capable autonomous-HVAC platform; CBRE runs Smart FM across a billion square feet with its Nexus data platform and Ellis AI assistant. Both are excellent at the analytical and automation layers, and their research arms make causal-sounding claims all day: the green premium, the flight to quality, the amenity that lifts rent. But that is market-level correlation sold as advice, the average across everyone’s buildings. It is not an owned, instrumented engine that proves what this building does to these tenants. And a broker has little reason to build that: the deep, asset-specific version is the client’s moat rather than its own, sits on an asset it may lose at the next tender, and needs commercial data owners guard. The broker’s economics reward the opposite, a shallow benchmark spread across a billion square feet. Useful, but not the same thing.
The more telling case is JPMorgan’s new headquarters at 270 Park Avenue: thousands of sensors, AI trimming light and temperature in real time, solar shades wired to the HVAC, all-electric and net-zero. JPM owns it, occupies it, and holds every scrap of commercial and workforce data needed to close the causal loop. A caveat: I am reading this from the outside, from what is public, so take it as inference, not fact. JPMorgan may do more behind closed doors than it says. But the public story is sustainability, intelligence and prestige, not causal proof of how the building changes the people and the business inside it, and a firm that had built the evidence engine would be telling that story. One of the most expensive and ambitious corporate headquarters ever built, and on the public record it still cannot show you whether the building earns its keep. It built the most advanced energy-and-experience building on earth, not the most advanced evidence building, because the causal-commercial question is nobody’s job. Buildings get commissioned against carbon, air quality, daylight, amenity and cost: legible, certifiable, defensible. Causal social science on your own workforce is messy and politically fraught, so even a firm with near infinite money defaults to the certifiable.
The gap, then, is not technology. The apex buildings are stuffed with technology. It is framing and incentive. The industry defines a smart building as connected and efficient and pleasant, and operates inside that definition brilliantly. The causal building asks a different question, and the brokers’ economics and the occupiers’ incentives both point away from it.
AI DID NOT GIVE YOU THE ANSWER
A fair challenge: hasn’t generative AI changed all this? It has, in one half and not the other.
Much of the optimisation was always possible and shamefully neglected; AI just removes the alibi by making it cheap. What is genuinely new is that frontier models can finally read the commercial half of the building, the leases and contracts and reports that were locked in PDFs, which is what lets you join how a building behaves to what it earns. That, plus agents that can act rather than merely build dashboards, is the real change.
But the causal core is the one thing AI does not hand you. A frontier model is the most articulate pattern-matcher ever built. Ask it why your renewals are sliding and it will give you a fluent, confident answer stitched together from correlation. Fluent is not the same as right. That is ‘workslop’ at the level of analysis. Causation comes from physics or from experiments, never from the model alone. AI is the connective tissue and the interface. It is necessary, and nowhere near sufficient.
The people building the biggest AI bets agree. In May, Anthropic launched a $1.5bn venture with Blackstone, Hellman & Friedman and Goldman Sachs to embed engineers inside portfolio companies and rebuild their workflows, with real estate named as a target. Days later OpenAI stood up a $4bn-plus ‘Deployment Company’ to do much the same. Their pitch is that the model alone changes nothing: the value is in the deployment and the redesign around it. They are right, and proving my point at scale. They will hand the whole industry the commodity workflow layer. But their incentive is to sell workflow transformation, not to build you an owner-controlled evidence substrate for your own portfolio, and you should think hard before renting your operational intelligence from a consortium whose anchor is one of the largest landlords on the planet. Rent the model. Own the substrate.
WHO THIS IS ACTUALLY FOR
It is not for everyone, and the reason is the holding period. Offices change hands every five to ten years on average, and the commercial-causal payoff matures over a lease cycle. If you are a three-year value-add buyer, do the energy layer that pays for itself and stop there.
For everyone else it stands up. It is built for the long-capital owners and the owner-occupiers, the pension funds and insurers and sovereign wealth and the firms that sit in their own buildings for decades: the natural owners of prime office, not a fringe. The right unit of return is not the building but the portfolio capability, which compounds across assets and outlives any single hold. It rests on a hypothesis, and I will flag it as one: that the market will learn to price causal proof of performance the way it learned to price energy, where green moved from unpriced to a measurable premium with a brown discount for the laggards. I think that bet is sound, and the early mover helps set the price rather than pay it.
If this were in everyone’s interest it would already be commoditised and worth nothing. It is precisely because the short-hold majority cannot justify it, and the brokers err away from it, that the long-hold owner who acts captures something durable. The misalignment is the moat.
And it is not only for new towers; the opposite is true. A shiny headquarters lets on prestige and need not prove it earns its rent. It is the commodity 1990s and 2000s office, staring down obsolescence, that most needs to prove its worth, and the substrate retrofits into exactly that building as a defence against it emptying. The hardest case is where the thesis pays best.
WHAT GREAT LOOKS LIKE
The perfect office is not the one with the most sensors or the cleverest app. It is the one that can prove what it does to the people inside it, built on a data substrate you own, with the frontier model as a commodity bolted on top and swapped out whenever a better one arrives. This is the Maven I described two years ago, finally handed the one thing it lacked: the means to prove itself. It is #SpaceAsAService with the evidence attached, and it is where ‘Human is the New Luxury’ stops being a slogan and becomes a number you can defend.
The technology is here. The methods are mature. The excuses are running out. What is missing is the will to treat a building as something that learns, and whether your buildings ever do is entirely down to you.
The AI Employee Trap
Augment everywhere. Agentise selectively. Own the judgement layer.

The industry is being sold ‘AI employees’ that cost orders of magnitude more than a chatbot and quietly take over the firm’s judgement. Augmentation pays back almost everywhere. Agents pay only on a narrow band of work, and most of what’s being sold sits well outside it. The skill that now separates the winners from the also-rans is telling the two apart.
A pitch crossed my feed last week: seven ‘AI employees’ for a real estate investment firm, plus an orchestrator running the lot around the clock and handing leadership a ‘real-time command centre’. It is a seductive picture. It is also, mostly, the wrong thing bought at the highest possible price. The reasons are worth your time, because the same logic decides where AI pays in your business and where it simply bills you.
Executive summary
Two kinds of AI are landing in commercial real estate at once, and they have opposite economics. Augmentation (AI as a thinking partner, around twenty pounds a month) makes expensive people sharper and pays back almost absurdly. Agentic systems cost one or two orders of magnitude more to run, and only pay when the work is cheap to check and the human time is dear. Most of what is sold as ‘AI employees’ fails that test: it automates the judgement that should stay human and bolts itself onto a deal process that ought to be redesigned. The firms that pull ahead will sort their own work before they buy anything, and will own the layer where their expertise meets the machine. The biggest stack is the booby prize.
SEVEN EMPLOYEES AND A COMMAND CENTRE
The pitch gives a real estate investment firm seven ‘AI employees’, each with a remit:
- Sourcing scrapes broker inbound, offering memoranda and listing platforms, and ‘kills 40-50% of deals before a human looks’.
- Market monitors public and proprietary data and flags regulatory, economic and asset-level risk.
- Comps tracks and analyses sales and lease comparables around the clock.
- Underwriting builds and updates models inside the firm’s own Excel templates.
- Intelligence watches the portfolio for risks and opportunities in real time.
- IC generates institutional-grade investment memos, diligence summaries and deal playbooks.
- Asset management tracks post-close execution, from hundred-day plans to monthly KPIs.
Over the top sits an orchestrator running all seven at once, always on, handing leadership a single ‘real-time command centre’ across deals, assets and operations.
The people who built this know real estate. That is exactly why it deserves a serious read, and why the flaws are instructive rather than embarrassing. The property knowledge is sound. The trouble lives in two questions the pitch never asks: what does it cost to run, and what does it cost to trust?
TWO MACHINES, TWO BILLS
A chatbot you use as a thinking partner answers in one pass. You read it, you push back, you decide. An agent works differently. It plans, calls tools, retries, checks itself, and drags a growing pile of context through every step. A single task can fan out into dozens or hundreds of model calls. So the running cost lands one or two orders of magnitude above a chatbot’s, and a system of seven agents plus an always-on orchestrator is the most expensive shape you can build: continuous machine thinking applied to data that mostly sits still.
At twenty pounds a month, AI as a thinking partner has return economics that are almost embarrassing to write down. Make a skilled analyst even a few per cent sharper and the maths is over before it begins, because the human already owns the judgement and, sitting right next to the work, checks the machine cheaply.
The cheap tool captures value per pound.
The expensive one earns its keep only where the human bottleneck is worth removing, and there a second truth takes over: at the apex of value, the compute cost stops mattering at all. Run a complex deal through three models wearing three analytical personas, and if one of them surfaces a structural risk that would have sunk a fifty-million-pound purchase, the token bill is a rounding error against the disaster avoided.
The waste was never the compute. The waste is spending it on lease comparables. Heavy machine thinking belongs where the stakes are highest and the judgement densest, nowhere near the work a junior clears in ten minutes. The bill only matters when the work doesn’t.
THE QUESTION THAT SORTS IT
So when does an agent earn its tokens? Two things decide it, and neither was on this vendor’s slide.
The first is how cheap the output is to check. If you can verify a result at a glance, you can let a machine run and simply catch the errors as they come. If checking the work costs nearly as much as doing it, the agent has saved you nothing and added a layer of risk for the privilege.
The second is how expensive the human time is that the agent displaces. Free a senior underwriter from an afternoon of model-building and the tokens are a rounding error. Automate a task a junior does in ten cheap minutes and you are paying a fortune to save loose change.
Put the two together and you have a rule you can carry into any vendor meeting:
*agents pay where the work is cheap to verify and the human time is expensive; everywhere else, augment the human and keep them in the loop.*
This is my CRE Automation Matrix doing its job. Sort the work by whether you can check it and what kind of work it is, and the safe ground for autonomy separates cleanly from the ground where AI should challenge a human and never replace one.
And before anyone objects that the cost is falling: the price of a given capability is dropping fast, but that is not the same as your bill falling. As tokens cheapen, consumption explodes to match (the Jevons paradox, in silicon), a hundred agents running around the clock where today you would balk at one, and the firms selling the tokens have every reason to cheer that on. Unit price drops; total spend holds or climbs. What cheaper compute never does is make unverifiable work checkable or turn a commodity into your edge. So whichever way the price curve runs, the discipline is the same: design efficient systems. Verification and differentiation decide whether to trust an agent at all; how well it is built decides what it costs you to run. And building it well is a lever only the firm that owns the system ever gets to pull.
NOW READ THE STACK
Run those seven ‘AI employees’ through the rule and they sort into three piles.
Put asset management in the pile marked safe. It comes last on the list, and it is the strongest thing on it. Tracking KPIs against plans is verifiable to the penny, the work is a genuine grind, and handing it to a machine is pure gain. The two monitoring agents, market and intelligence, belong there too, on one condition: a human acts on the flag, rather than the machine acting for them.
Put underwriting and comps in the pile marked handle with care. Building a model inside the firm’s own template is genuinely useful and easy to check, so long as the agent does the mechanical build and a human still owns the assumptions: the rent growth, the exit yield, the voids. The moment it sets those for you, it has automated the judgement and left you checking arithmetic, and a tidy model carrying plausible wrong numbers is more dangerous than an obviously broken one. Comps has the same shape plus a data problem: private-market comparables are lumpy and lagged, and ‘around the clock’ is mostly marketing.
Then the pile I would mark dangerous, which is, tellingly, the one the pitch leads with. Sourcing sits first on the vendor slide, and ‘kills 40-50% of deals before a human looks’ is sold as efficiency when it is really a hidden tax on your edge. A tired associate skimming a hundred memos misses good deals too, and brings their own biases to it: favoured sponsors, familiar geographies, the assets that look normal. But those biases are plural and contestable. A team carries many of them, they argue in the room, and a killed deal can be reopened. A model collapses all of that into one bias, applied the same way to every deal in the funnel, with nobody watching it happen.
Picture a rifle sighted three inches left: it misses identically, every shot, without a sound. In a business where the return so often lives in the deal that looks wrong on paper, that single silent screen running across the whole funnel is how you automate away the very thing you are paid to spot. A panel of models does not save it: they are trained on the same internet and tuned toward the same notion of sensible, so they share most of the blind spots and merely reject more confidently. And a sharper screen is the wrong goal at the mouth of the funnel, where the job is to keep the odd-looking deal alive rather than bin it more efficiently. The IC agent fails in a subtler way. A machine helping to write the memo is fine; the danger is the memo becoming a substitute for the analyst’s conviction. An investment memo should be the compression of hard-won judgement. If the machine produces the prose before the human has done the thinking, you get confident ‘Workslop’: shallow analysis laundered into the house style of rigour.
WHO CHECKS IT, AND IS IT WORTH IT
Notice what the rule forces you to hold in mind: two separate questions, not one. Can you trust the output? And is it worth the spend? The vendor only ever pitches the second, and answers it with a saving on cheap human attention.
There is a deeper point, and it is the one I would watch most closely. Where a task lands on that matrix is not fixed by the task. It is decided by how well the system is built. A poorly designed memo agent that emits polished prose from a black box is unverifiable by construction, and lives in the danger zone. A beautifully built one that shows its sources, exposes its reasoning, and stops to ask a human to sign off the assumptions becomes checkable, and moves the same task onto safe ground. Same job, opposite outcome. The difference is craft.
Which is why most of these stacks disappoint. They take the firm’s existing process and bolt agents onto it. We spent two decades ‘digitising the past’; this is the same instinct, now ‘AI’ing the past’: automating a workflow that should have been redesigned. The orchestrator’s ‘command centre’ is the tell. It sells leadership the feeling of control while removing the human from the loop, then stacks seven error rates on top of one another and hides the total under a tidy dashboard.
THE EDGE IS THE LAYER
This reframes the build-versus-buy question every firm is now circling. The instinct is to ask whether to build a stack in-house or buy one from a PropTech. Both framings miss where the value sits.
A PropTech selling one stack to many firms has to generalise somewhere. The real question is whether it generalises away the very thing that makes you distinctive. It can hire a clever ex-broker, but it cannot encode your particular judgement and then sell that same product to your competitor. The generic stack, by its nature, cannot carry your edge. Build in-house and you meet the opposite trap: deep property knowledge wedded to naive system design, reproducing the vendor’s mistakes bespoke and at greater cost. Domain experts reliably underrate the craft of building these systems, for the same reason the vendor underrates the verification economics. Each side is strong precisely where the other is weak.
So the better question is about neither building nor buying. Both miss the point. The value sits in who owns the layer where your domain knowledge meets the machine’s capability: the instructions, the checks, the inputs, the process design. That layer is the moat. Give it a name: a Skill (the format devised by Anthropic, now an open standard). A portable, refined body of instruction that captures how your firm reads a building, prices a risk and walks away from a deal, the explicit rules and the tacit gut of your best operators alike, and rides on top of whatever foundation model is state of the art this quarter. The models will keep leapfrogging one another and converging on price. The Skill is the part that stays yours. It is also, conveniently, the one part you can own without building the underlying technology at all, by taking a general-purpose model and pouring your own expertise into how you instruct it and how you verify it. Your edge comes from nailing every input and every process. The model is a commodity. The judgement you encode into how it is used is not. Human is the new luxury, made operational.
But own that layer only where the work actually sets you apart. This is the old distinction between core and context, and it cuts both ways. Where a task is the source of your edge, the judgement your clients pay you for, build it, encode it, guard it, and never let a vendor turn it into something it also sells the firm down the road. Where a task is commodity work that every firm does much the same way, do not build it yourself either. Buy the generic tool and point your scarce design effort at the work that compounds.
This answers the value question as much as the build question. Your real differentiators tend to live in the hard-to-verify work: the investment thesis, the taste, the relationship, the call on the deal that reads wrong on paper. That is the work to automate least and own most, because it is where your returns concentrate and the one thing a competitor cannot buy off the shelf you used. Spend there. Industrialise everything else.
START WITH YOUR OWN DESK
So before you buy a single ‘AI employee’, do the unglamorous work. Write down your firm’s real tasks. Against each one, ask three things:
how cheaply can you check the output,
how expensive is the person doing it now,
and is this where your edge actually lives.
Augment everywhere: that twenty-pound thinking partner belongs on every desk. Hand to an agent only the work that is cheap to verify and dear in hours. Build and own only where the work sets you apart. Buy the rest, and feel no shame in it.
Off the Yellow Brick Road
Get clear which road you’re on. Then stop watching the other one. Focus, focus, focus is the new location, location, location.
WHERE WE LEFT IT
Three arguments here over three weeks. CRE is two industries under one name, and AI hits each differently. The middle layer of PropTech is hollowing out as buyer-builders take it in-house. The consortium deals are a game mid-tier operators should refuse to imitate.
For years, CRE technology came from two places: a startup sold you software, or you built your own. The incumbents sat beneath both as the systems of record. AI has added two more players. The labs are taking the horizontal work directly. The consortia are taking the repeatable middle. Five kinds of player now compete across the same ground, and the only useful question is where each should stand.
A piece from Andreessen Horowitz, published the same week as the last of those three, gives us the map to answer it.
WHAT THE VC SIDE JUST SAID
Joe Schmidt, partner at a16z, published Avoiding Death on the Yellow Brick Road on 27 May. It is, in Roger Martin’s terms, a where-to-play map. The labs own the Yellow Brick Road: horizontal, low-step coworker work that improves with raw model capability. Everything else lives in the Rest of Oz: vertical, multi-step, regulated, judged on customer P&L rather than benchmarks. Both can win. Most application-layer startups will die because they walked onto the road.
The Rest of Oz survives the labs on four defences, Schmidt argues: data flywheels, model routing across vendors, cost optimisation across model tiers, and governance that absorbs regulatory complexity for the buyer. Three tests tell you whether you are on it. The tools-and-steps test: how many steps does the work take, and how complex are the tools beneath it? The system test: are you the system the customer runs work through, or a tool sitting on one they already have? The P&L test: are you judged on customer outcomes, or on benchmark scores?
Apply this to CRE and the diagnosis from the last three pieces survives intact. The middle layer of cognitive workflow software dies. Generic AI-for-X PropTech fails all three tests. As last week’s piece argued, the buyer becomes the builder where the work carries its proprietary edge. Schmidt adds the other half from the venture side: the startup wins where it owns the system of work, not where it wraps a tool around someone else’s system. Two people landing on one diagnosis from opposite ends of the industry is the closest thing to validation an argument like this gets. The three tests are also sharper than anything in the trilogy; use them on whatever you are buying or selling.
THREE TERRAINS, FIVE PLAYERS
Translate the map to CRE and there are three terrains, not two. The Yellow Brick Road carries generic coworker work. Between it and the deep country sits Mid-Oz: vertical-ish work, repeatable and configurable enough to standardise across firms. The deep Rest of Oz is the domain-specific, multi-step, regulated, judgement-heavy work that cannot be built from generic capability alone.
Now put the five players on that ground.
The labs own the Yellow Brick Road and reach into the edges of Mid-Oz. The consortia — Anthropic’s enterprise AI venture with Blackstone, Hellman & Friedman and Goldman Sachs, and OpenAI’s Deployment Company — are built to industrialise Mid-Oz, standardising repeatable workflows across the companies they deploy into. They have the capital to do it. They are not the only ones who can. The deep Rest of Oz belongs to two kinds of player: operators who build their own systems, and startups that own a single painful, regulated, commercially material process end to end and get better at it with every deployment. The incumbents sit beneath all of it, across the systems of record.
That is the where-to-play map. The two new entrants, labs and consortia, arrived with clear remits. The three players who were already here — incumbents, startups and operators — now have to relearn where their advantage lives. Take them in turn.
THE INCUMBENTS HAVE LOST THEIR FREE PASS
The first is the incumbents. Yardi, MRI, Argus, CoStar, MSCI/RCA hold the systems of record and the data primitive layer. Schmidt predicts they survive: whoever owns the system of work survives the labs. The position is theirs to lose, and it is defensible. They are also, on any fair read of their fifteen-year record, the firms in CRE least obviously equipped to execute on AI at speed.
That did not matter before. They were unassailable. Switching costs measured in years, certifications in decades, relationships in golf-course-time. They did not need to be good at innovation because nothing they did was contestable. Argus has long been the sector’s byword for standing still. None of these firms has been a natural home for ambitious AI talent. None of it cost them their position.
It does now. The position has not become indefensible; the cost of defending it has gone up. While still unlikely, it is no longer impossible that an embedded operating system gets supplanted, worked around, or abstracted away from being critical. The three challenger paths I named last week — operator-spinout architectures, specialist services-as-software vendors, and lateral entries on incumbent failure points — can each take meaningful share without dislodging the incumbent outright. None of those routes had credible AI-driven economics eighteen months ago. All of them do now.
So the incumbents win this round by default, and have to play the next one properly. The free pass on execution and innovation is the thing that has changed. Should win is carrying real weight in that phrase. Whether they will is no longer the irrelevant question it has been for fifteen years.
THE EASY STARTUP IS DEAD
The second is the startup, the player Schmidt is really writing about and the one whose ground has moved most. His argument is widely misread as “the labs kill startups”. It is narrower. The labs kill the lazy startup. A model wrapper, a reporting overlay, a generic AI-for-real-estate copilot on someone else’s system: the road absorbs all of them.
The startup that survives owns a system of work. It takes one painful, multi-step, commercially material CRE process and becomes the place that process happens, capturing the workflow data, the governance and the record of what was done. It picks ground where the incumbent is too slow to follow, the operator cannot justify building alone, and the labs cannot learn the domain from outside. And it gets better at that one thing with every deployment, which is the one moat Schmidt thinks survives contact with the labs.
That is a narrower opening than PropTech has enjoyed for a decade. It is also a more defensible one. The winning CRE startup will not sell AI into the industry. It will take a slice of the industry’s work and own it end to end.
THE OPERATOR DEFAULT IS DATED
The third is the operators. The default setting for almost every CRE operator today is buy. That setting is rational. It is also dated.
When sophisticated operators made their AI decisions through 2024 and 2025, the build path was not credibly open to a mid-tier firm. Agentic infrastructure was immature. Models could not yet do agentic work reliably enough for a mid-tier firm to bet on them. Skills frameworks barely existed. Forward-deployed engineering for mid-market operators barely existed. Buying from an incumbent or a specialist vendor with the infrastructure already in place was the right call.
It is a different call today, and will be different again in 2027. AI capability is improving fast enough that any tooling commitment is now a bet on which curve is steeper: the buy partner’s incremental AI delivery, or the operator’s own build option as the underlying tools become generally available.
Sam Altman has made this point to founders for years. Build assuming the models keep getting better, not assuming they stay still. He reckons 95% of founders should bet on continued improvement; most bet the other way and end up as the “OpenAI killed my startup” meme. The advice travels to a sophisticated CRE operator unchanged. What is impossible to build in-house this year may be routine next year. The work an operator treats as its distinctive edge may be buildable in-house the year after.
None of this says build everything, or that buying today is wrong. It says the buy decision now needs making with one eye on whether what you are buying is still the right thing across the life of the commitment.
For now, an operator’s tacit knowledge is proprietary. The consortia are the most visible mechanism that changes it. Forward-deployed engineers embedded across enough client firms observe how each one operates, then aggregate what they see into a standardised method the whole industry can buy. Every deployment makes the next operator’s edge a little less distinctive. The window between proprietary and commoditised is open now, and the cost of building tools to capture your knowledge in your own systems before it shuts is falling fast.
DIRECTION OF TRAVEL
Put the map and the three moving positions together, and the takeaway is easy to state and uncomfortable to act on.
The field has five players now, not the two it had when the only question was build or buy. The labs own the road. The consortia are industrialising the middle. The incumbents hold the systems of record but have lost the free pass that let them coast. Operators and startups contest the deep country, where the real systems of work get built.
So the question is not whether AI changes your corner of CRE. It is which of the five you are, and where on this ground you can win. Most of the industry will treat that as too early to act on. By the time they do not, the positions will have been taken.
The Wizard is buying road. The land is shifting faster than the road is being laid.
The best new PropTech is a CRE company
Fifteen years of 'buy don't build' was the right answer. AI has flipped it.
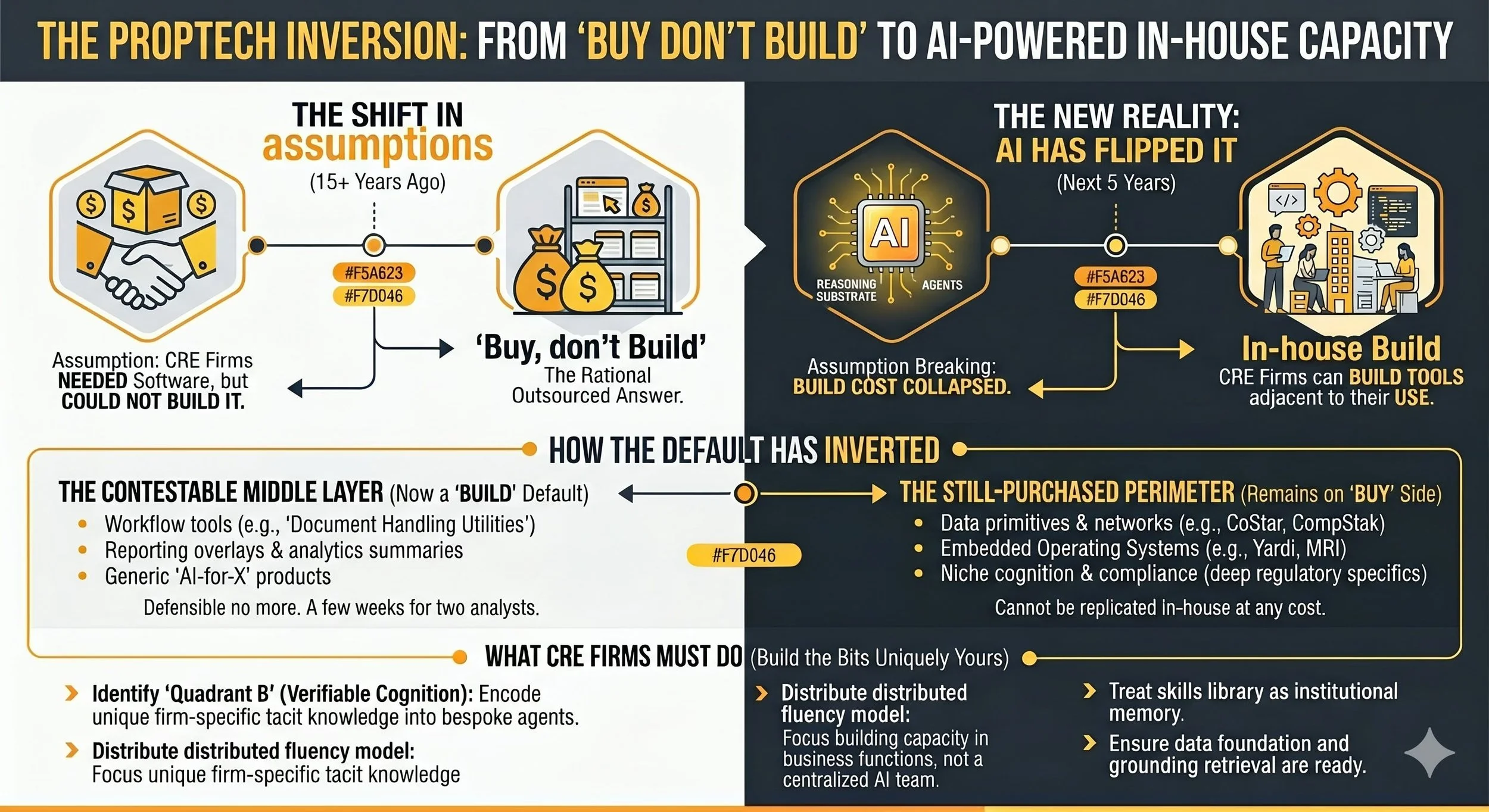
Fifteen years of ‘buy don’t build’ was the right answer. AI has flipped it. The most consequential new property technology of the next five years will be built inside the firms that need it, not sold to them.
I have written about PropTech, and argued with PropTech founders, for three decades. The assumption underneath the whole industry has been that CRE firms need technology, but cannot build it. That assumption is structurally breaking, and not for the reason most commentators are reaching for. The cause is more interesting than build cost alone: the ‘firm’ itself is becoming something different, and the people inside it are becoming something different. What follows is what that means for which PropTechs survive, and for what your firm should be doing inside its own walls.
Executive summary
The PropTech industry has spent fifteen+ years on one assumption: CRE firms needed software they could not build themselves. That assumption is now breaking. Build cost has collapsed for domain experts who hold the relevant knowledge, and the working life of the typical CRE professional is reshaping around agent orchestration in a way that makes building feel adjacent to using. Together those two shifts have inverted the ‘buy don’t build’ default. The middle layer of PropTech, the workflow tools and reporting overlays and generic AI-for-X products, is now contestable from inside the buyer. Data networks, embedded operating systems and deeply specialised regulatory tools remain on the buy side. PropTech founders need archetypes that survive this shift; CRE firms need to recognise that their next competitor for cognitive workflows is increasingly themselves.
WHAT HAS ACTUALLY CHANGED
The argument rests on two things happening at once. They reinforce each other, but they need to be seen separately to be understood properly.
The build cost has collapsed
A senior surveyor with access to a properly configured reasoning substrate, a small library of firm-specific skills, and an afternoon free can now produce working tooling that a Series A PropTech would have needed eighteen months and three engineers to ship. Run a ‘Layer 1’ deployment inside most firms that have done the data work, and the demonstration sits on a desktop within days or a few weeks.
That collapse changes the economics of in-house build in a way the industry has not yet absorbed. The old buy-versus-build calculation assumed building required engineers the firm did not have, infrastructure it did not run, and time it could not afford. All three lines have shifted. Two of them have shifted profoundly. The CRE firm that runs the numbers today reaches a different answer than it did in 2020.
That is the supply-side change. It is real and increasingly understood.
The firm is becoming something different
The more interesting change is what the firm itself is becoming, and how that affects who can build what.
Over the next three to five years, the working life of the typical CRE professional will reshape around agent orchestration. The substance of their job, not a layer on top of it. The discipline is curation. The day’s work is orchestration. Scope the task, configure the agent, validate the output, decide what to do with it. That is a different kind of professional, doing a different kind of work, embedded inside a different kind of firm.
Which matters for the buy-versus-build question. The muscle memory of curating an agent is adjacent to the muscle memory of building one. The capability ladder has fewer rungs than it used to. Curating output is the entry-level discipline. Codifying workflow is the next. Building internal tooling is the next after that. Each rung is a smaller step than it was, and the people climbing them are already on payroll.
What this means in practice is straightforward and largely unannounced. Knowledge workers are beginning to build their own software. Not full enterprise systems. Not the platforms procurement signs annual licences for. The specific cognitive tools they need to do their work better tomorrow than they did today. A property lawyer encoding her firm’s approach to lease abstraction as a skill. An asset manager configuring a covenant-watch coworker that flags exposure shifts across the portfolio. A development director building an agent that runs first-pass appraisals against the firm’s house assumptions. None of them call this ‘building software’. They are.
The same shift is visible in the startup ecosystem. The domain expert who used to need a technical co-founder, a contract dev shop, or eighteen months of runway can now be the hybrid technical founder. The surveyor who knows exactly why ARGUS produces unreliable reversionary valuations in a rising yield environment can build directly against that problem. The fund manager who has watched three IC processes fail at the same point can build the fix herself. Both phenomena have the same cause. Both have the same consequence for the buy-versus-build question.
This is the organisational shift that makes the inversion structural rather than situational. The professional class in CRE is not being replaced by AI. It is being restructured around it. That restructuring is the precondition for in-house build to feel natural rather than foreign.
One caveat worth holding in mind. This describes firms that have done the organisational work to support agent orchestration. Most have not yet. For firms still running on conventional structures, deploying AI on top produces automated dysfunction at machine speed, not compounding capability. The thesis applies most strongly to firms that have crossed the organisational threshold, less to those that have not, and not at all to firms that refuse to. The middle layer of PropTech does not die uniformly. It dies at the frontier first, with the customers vendors most need to retain.
For commercial real estate, this restructuring maps directly onto Quadrant B (see previous newsletters) of the CRE Automation Matrix: ‘verifiable cognition’, where firm-specific tacit knowledge gets encoded into firm-specific agents that handle the high-value cognitive work the firm actually does. Quadrant B is where the durable differentiation lives, because the knowledge being encoded is yours and not your competitor’s.
It is also where the buy-versus-build calculus tilts most sharply toward build. The value of Quadrant B work is precisely what makes it un-standardisable. Any vehicle that promises Quadrant B at scale will, by its economics, push toward generalised patterns that work across many firms. The patterns that work specifically for you have to be built by people who know what ‘specifically for you’ actually means. Mostly that is you.
One further dependency. Quadrant B sits on top of the lower layers of the stack. The data foundation has to be reasonable. The reasoning substrate has to be deployed. Grounded retrieval has to be working over firm data. None of that is exotic in 2026, and none of it is free either. The firm that wants to do meaningful Quadrant B work in-house needs to be comfortable with most of the layer cake, not just the top tier. The full architectural argument is in *CRE AI Is a Layer Cake*. The short version: sequencing matters, and the firms that try to start at Quadrant B without the lower layers in place produce the productivity theatre they were trying to avoid.
WHO MAINTAINS WHAT
The obvious objection to the argument so far. Prototypes are cheap. Enterprise capabilities are not. Maintenance, governance, audit, security, integration. None of these has been collapsed by AI to anywhere near the degree first build has. Anyone who pretends otherwise has not actually shipped software inside a regulated firm.
This is half right. The objection assumes the in-house build resembles the old in-house software project: bespoke infrastructure, custom code, internal devops, full-stack ownership. That is not what serious firms are building.
What they are building sits in the upper layers of the stack, on top of platforms the model providers maintain. Configured agents. Skills libraries. Projects. Grounded retrieval over firm data. The model, the orchestration, the security baseline, the inference reliability. All of those are maintained by the platform, not by the firm. The firm maintains the configuration, the prompts, the data connections, the access controls, and the management structure that curates the lot.
The shape of that management structure matters more than most operators realise. The firms doing this well will have built a distributed fluency model: domain experts as builders inside business functions rather than seconded to a central AI team, stewards governing a skills library treated as institutional memory, evaluation infrastructure detecting drift before it bites. The talent-dependency problem of ‘one analyst built it, nobody understands it after she leaves’ is real for firms that have not done this organisational work. It is largely engineered out for the firms that have.
That is a different maintenance problem to the one PropTech sales teams have spent fifteen years warning operators about. The cost is real. The shape is manageable. Any firm that can run a quality management system for its asset data can run one for its skills library and its agent configurations. Where deeper maintenance is genuinely required (bespoke integrations, regulated workflows with full audit chains, mission-critical systems), you bring in partners who manage those workloads professionally. The same way you bring in audit, legal or quantity surveying for the work you do not staff internally.
What you do not do is build random demo-quality apps and pretend they are enterprise systems. That route was always a bad idea and it still is. The category of build worth doing is the category that lives in your firm’s distinctive judgement and benefits from compounding inside the firm. Quadrant B work. Not everything. Not infrastructure. Not commodity workflows. The cognitive workflows where the value sits in your house view of the world.
AI has not made governance optional. It has made ownership newly plausible.
THE INVERSION
The default has flipped.
For fifteen+ years, the right answer to a CRE technology question was almost always ‘buy, not build’. The reasoning was solid. Building required engineers the firm did not have, infrastructure the firm did not run, and time the firm could not afford. The PropTech industry was the rational outsourced answer to a problem the industry was not equipped to solve internally.
That answer was right. It is no longer right for a meaningful slice of what PropTech used to sell.
The slice that has flipped is the middle. Workflow tools that automate cognitive labour. Reporting and dashboard products. Analytics overlays that summarise what other systems already hold. Document-handling utilities, IM drafting accelerators, lease review tools, and most of what is currently described in pitch decks as ‘AI for [X workflow]’. These products were defensible when the alternative was a serious in-house dev project running into years. They are increasingly indefensible when the alternative is two analysts, a Claude subscription, and a fortnight.
The default has not flipped everywhere. Three categories remain firmly on the buy side. Data primitives and networks (CoStar, CompStak, the major brokerage networks) cannot be replicated in-house at any cost, because the moat is contributed data the firm does not own. Embedded operating systems (Yardi, MRI, RealPage, ARGUS) carry years of accumulated process logic, regulatory certifications and integration depth that no internal team can recreate inside a sensible budget. Niche cognition tools with deep regulatory specificity (UK SDLT optimisation, US 1031 exchanges, German Wohnen rules, BNG tracking) live in markets too narrow and too specialised for any single firm to justify in-house work, and the specialist who serves the whole market amortises the rule library across all of them.
Outside those three categories, the default has moved. The answer is now ‘build the bits that are uniquely yours; buy the bits that aren’t’, and the boundary has shifted to give ‘uniquely yours’ a much larger surface area than it had five years ago.
This sounds like a small adjustment, but in reality it is a structural one. The PropTech industry was built around an assumption that the buyer could not be the builder. For the next five years, the buyer increasingly is the builder. The competition for most middle-layer PropTech is no longer another PropTech start-up. It is the CRE firm’s own internal capability, supplied by people who already work there.
Both sides of the market have to absorb this.
WHAT SURVIVES
The inversion clarifies rather than kills PropTech.
What remains genuinely defensible falls into four archetypes. Three exist outside the inversion entirely. The data, infrastructure and specialist categories no in-house build can replace. The fourth is the shape new PropTech takes when the inversion lands: operator-built tools that get spun out.
1. Data primitives and networks
Multi-sided businesses where the moat is contributed or observed data that no single participant could assemble alone. CoStar, CompStak, MSCI/RCA, the major brokerage transaction networks. AI makes genuine network-contributed data more valuable, not less, because it becomes the structured ground truth every AI agent in the industry consumes. However, the category is narrower than the named brands suggest. Data that was merely hard to assemble, involving proprietary scraping, manual research teams, ops you used to need scale to fund, is now increasingly easy to reconstruct. Some businesses currently classed as data primitives sit on the weaker side of that line.
2. Embedded operating systems
Yardi, MRI, RealPage, ARGUS, Tramps, Qube. Workflow lock-in across years, regulatory certifications, complex switching projects, integration depth no internal team can recreate. AI strengthens the incumbents who layer it on top of their existing footprint, because the existing footprint is the asset.
A frontal AI-first challenger PMS is unlikely to win. However, an agent-native operating layer that starts at a specific incumbent failure point, captures workflow-specific data, and gradually becomes the system of intelligence above the system of record is a different proposition, and remains plausible. Particularly in various niches. Mid-market BTR. European multifamily compliance. Single-jurisdiction lender reporting nobody serves well. The lateral entry, not the frontal attack.
3. Niche cognition and compliance tools
The regulatory and structural complexity that generalist AI gets systematically wrong, and that no single firm can justify tracking in-house. UK SDLT optimisation for cross-border investors, German Wohnen rules, US 1031 exchanges and LIHTC modelling, MEES compliance, the UK service charge code, biodiversity net gain, embodied carbon under RICS WLCA, SFDR and EU Taxonomy reporting.
The moat is two-sided: deep edge-cases a generalist team would get wrong, and a moving regulatory target the specialist amortises across hundreds of customers. Ideally founded by a domain expert who personally encountered the problem and now codifies it. The CRE firm trying to track this in-house discovers what ‘compliance debt’ looks like.
This category sits firmly on the buy side. The specialists who serve the whole market amortise the rule library and the regulatory tracking. You would not.
4. Operator-built tools that get spun out
The route to market that probably defines the next five years. Tools built inside major CRE firms (Blackstone, Brookfield, Hines, Greystar, Landsec, and their equivalents) for their own use, validated against billions of AUM, then spun out as commercial products. Operator credibility. Workflow validation against assets that actually exist. Pre-built distribution through the originating firm’s network.
Spinouts work best when distribution is non-competing: a different asset class, geography, or market segment from the originating firm. Vicinitee, which I founded and co-developed with British Land and which Equiem later acquired, ran on exactly that logic. Most of the credible new PropTech I expect to emerge between now and 2030 will come through this path, rather than through VC-backed SaaS founded outside the industry.
The pattern underneath the four
The four archetypes share a test. The PropTech that survives is the kind an incumbent cannot easily extend into, an in-house team cannot easily build, and a generalist AI cannot easily replicate.Most of these pass two. The best pass all three. Anything that fails all three is exposed, regardless of pitch deck or capital raised.
For a tech founder, the archetype tells you whether the idea has a future. For a CRE firm, it tells you what is still worth buying, and what to start building.
HOW INCUMBENTS GET OUTMANOEUVRED
The first two archetypes look unassailable. Data primitives like CoStar and embedded operating systems like Yardi have spent decades accumulating moats that no challenger can match head-on. The conventional wisdom says do not attack them, route around them.
The conventional wisdom is right. There are three credible ways through.
1. The over-the-top intelligence layer
Features accelerate a step in an existing workflow. Agents own the workflow and make the step structure obsolete. That distinction matters most where the workflow lives across multiple incumbent systems.
The CRE technology stack is a mess. Yardi, MRI, RealPage, ARGUS, CoStar, and dozens of point solutions. Each holds part of the picture. None can credibly offer the integrated reasoning layer above the lot, because each has an interest in privileging its own data. A vendor whose business model depends on its ecosystem cannot honestly treat its own data as one input among many.
That structural conflict is the opening. An intelligence layer that ingests data across legacy systems, resolves their inconsistencies, and provides unified reasoning is something the incumbents cannot match without cannibalising their own subscription revenue. The reader who has watched a quarterly portfolio review knows the operational gap intimately. The data lives in seven systems. The decision needs all seven.
There is a caveat worth flagging. MCP and standardised agent protocols are compressing the integration work this play depends on. The intelligence layer was a moat in 2024 because connecting systems was hard. It is increasingly available as infrastructure rather than as a defensible product. The play still works, but more as a capability CRE firms build for themselves than as a venture-scale category. The buyer-is-the-builder logic of this whole piece bites here too.
2. Attacking specific incumbent failure points
Frontal attacks on embedded operating systems are nearly dead. Lateral entries are not. The incumbents have structural blind spots, and challengers who concentrate on a single underserved segment can build credible positions before the incumbent notices or chooses to respond.
Mid-market BTR. European multifamily compliance. Single-jurisdiction lender reporting nobody bothers to do well. Niche operator categories where the incumbent product is genuinely poor, the customer base too small to interest the incumbent but too important to leave underserved. The play works because the incumbent’s economics push it toward broad horizontal capability, not toward deep vertical excellence. The gap is permanent. The opportunity is not.
3. Services-as-software
The most underappreciated of the three. Buyers do not want software. They want the work done. The traditional PropTech model sold a tool that helped a customer do work. The services-as-software model sells the completed work itself, with AI doing the heavy lifting inside the vendor.
The customer receives the maintained compliance evidence file, the lender reporting pack, the rent reconciliation, the planning submission draft. The customer sees outcomes, never software. The vendor takes the professional risk and prices the output rather than the seat. The model bypasses incumbent OS systems entirely. It competes for the result rather than the workflow.
The reason this is durable in CRE specifically: most of the high-value work is regulated, professional, and accountability-bearing. AI can do the cognitive labour, but somebody has to sign off. A services-as-software vendor that takes that liability captures margin no SaaS product could justify. The closest analogy outside CRE is the rise of in-house legal teams backed by AI-augmented external counsel: clients pay for the outcome and the accountability, not the tool that produced them.
What the three share
Each play routes around the incumbent’s strength by attacking from a direction the incumbent cannot credibly defend. The over-the-top layer attacks the closed ecosystem with openness. The failure-point play attacks horizontal breadth with vertical depth. Services-as-software attacks workflow ownership with outcome ownership. Each is a route through territory the incumbent built without considering this kind of competition could exist. AI is what makes all three economic. The incumbent has the data and the workflow. The challenger now has the cognition.
SO WHAT NOW
If you are running a PropTech, the question is whether your archetype is in the four. If it is, the question is whether you pass at least two of the three tests. If it is not, the question is how quickly you can move into one that is. The conventional answer is to raise more capital and grow into defensibility. The current answer is that capital does not buy you past any of the three tests. Adding scale to a category the inversion has hollowed out is a more expensive way to discover you have built the wrong thing.
If you are running a CRE firm, the question is which of your differentiating workflows you have allowed to live inside a vendor’s product. The default has moved. The vendor lock-in you have been managing was the right risk to take in 2018. It is the wrong risk to be carrying in 2027. The work of pulling Quadrant B back inside the firm is unglamorous, slow, and unavoidable. It also compounds. Buying rarely does, in the workflows where your judgement is the asset.
There is a larger question the industry has not started asking out loud. The PropTech category was built around venture capital and the assumption that scale follows product. If most of the surviving archetypes are not venture-scale, what happens to the category as a category? My current view is that PropTech contracts as a separate VC asset class over the next five years, and value capture migrates from venture investors back into the operator firms that now have the means to build for themselves. The category does not disappear. It gets absorbed.
The best new PropTech is a CRE company. Sometimes this is a literal claim about a tool spun out of a real estate firm with a £20bn portfolio behind it. More often it is the smaller claim that the most consequential property technology of the next five years was built inside the firm that needed it, by people who already worked there, and never reached the market at all.
For fifteen years, the smart firms bought what they could not build. For the next five, the smart firms will build what others would have sold them. The firms that see this first will spend the time quietly compounding the capability that the rest of the industry will eventually have to procure from someone.
Probably them.
Are you in the wrong half of Real Estate?
The 4-quadrant framework for surviving the hollowing out of the industry’s analytical core.
Last week we covered Pierson Ferdinand: 270 partners, no US associates, AI doing what juniors used to do. That was the firm-structure scale of a dynamic that has been building for two years. This week the capital-deployment scale arrived, and arrived with two frontier AI labs at once. The convergence forces a question on the industry: is real estate still one career? It plainly is not. The bifurcation has begun, and it is going to define the next ten years of who gets paid, who gets promoted, and which firms still exist in 2035.
EXECUTIVE SUMMARY
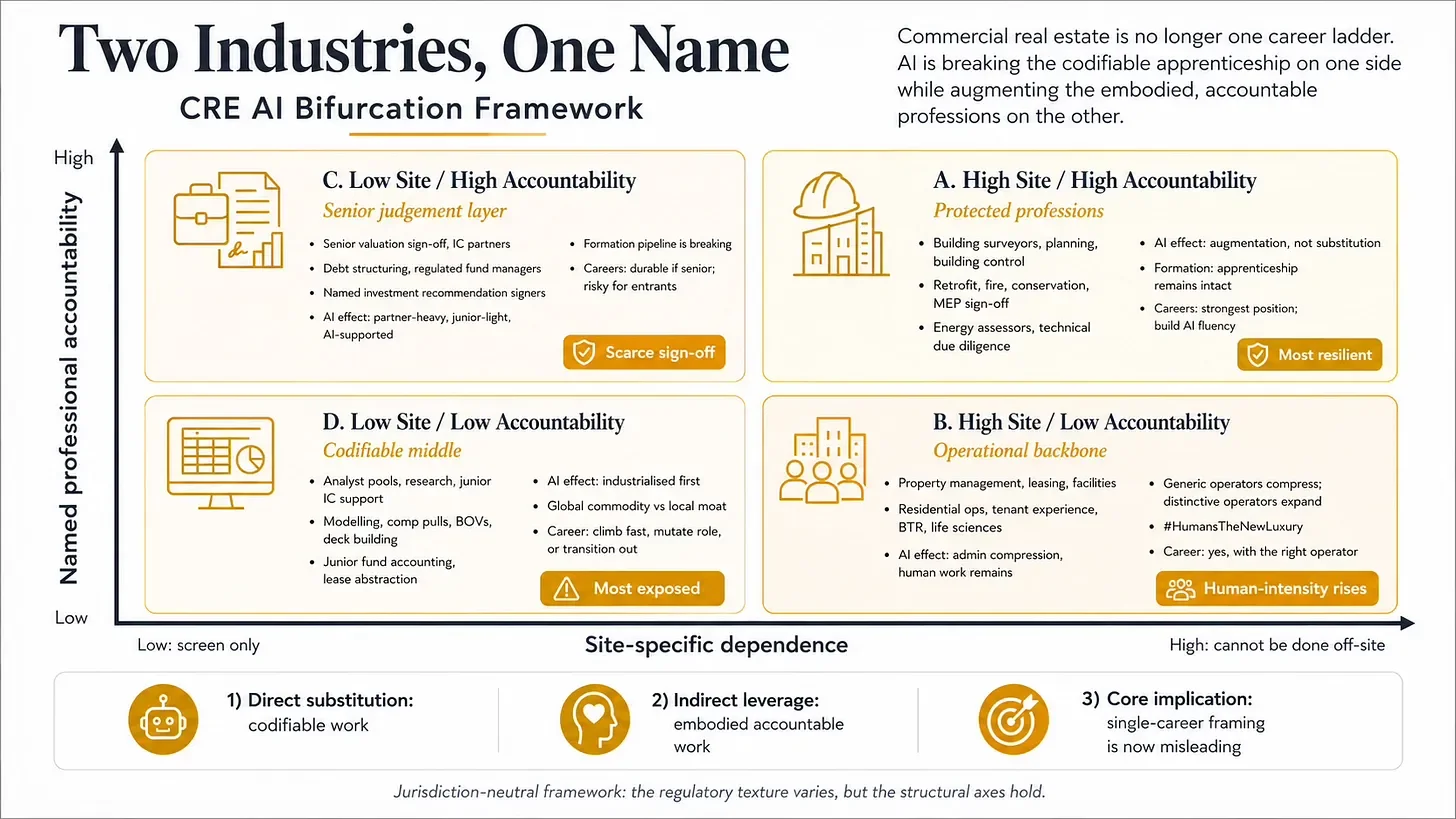
The first week of May 2026 produced three apparently separate signals: MetaProp Labs released a public catalogue of CRE-specific AI Skills; Anthropic announced an enterprise services firm with Blackstone, Hellman & Friedman and Goldman Sachs; and OpenAI reportedly raised over $4bn for a PE-backed deployment company carrying a reported 17.5% guaranteed annual return for its sponsors. Read together, they describe a single dynamic: AI is industrialising the codifiable, financial-instrument layer of CRE far faster than it is changing the physical-asset layer. This piece offers a two-axis framework: site-specific dependence and named professional accountability. The result is four quadrants with materially different futures. The strategic implication is that single-career framing is now actively misleading. Locating yourself accurately is the precondition for everything else.
THE WEEK THE BIFURCATION BECAME UNMISSABLE
Three things happened, and they look unrelated until you notice they aren’t.
MetaProp Labs published a public catalogue of CRE-specific AI Skills: machine-readable, downloadable, free to install across Claude, ChatGPT, Copilot and Gemini. Deals, asset management, leasing, accounting, legal, investor reporting. It is the public-tier expression of a much larger movement: codifiable industry expertise, packaged for portable consumption, available to anyone with a browser and an API key.
Anthropic announced a new enterprise services firm with Blackstone, Hellman & Friedman, Goldman Sachs and a consortium of further alt-asset managers. The firm will place AI engineers inside portfolio companies to bring Claude into core operations. Blackstone, for the avoidance of doubt, owns more commercial real estate than anyone else on earth.
The same week, OpenAI reportedly raised over $4bn from Brookfield, TPG, Bain and others to launch a competing deployment company, valued at $10bn, majority-owned by OpenAI, with a reported 17.5% guaranteed annual return promised to its private equity backers over five years. If accurate, that detail is the tell. It is a financial-engineering product as much as a technology rollout. The return is not earned on growth. It is earned on compression.
Three artefacts. Three scales: public-tier skills, consortium-tier deployments, capital-tier returns guarantees. One underlying dynamic the industry has not yet named clearly enough.
THE PUZZLE
The intuitive readings are familiar. The optimistic version: AI is industrialising in CRE, the pie is getting bigger, mass-market access to institutional-grade thinking is finally possible. The pessimistic version: the pyramid is breaking, most current jobs disappear, the industry is heading for the same compression as investment banking.
Both readings are incomplete. They share an assumption the events of this week ought to make untenable: that CRE is one industry on one trajectory.
Look at the three artefacts again. The MetaProp Labs catalogue is overwhelmingly aimed at the analytical layer of CRE: deals, asset management, investor reporting, accounting. Pierson Ferdinand is a law firm, a pure financial-instrument-layer professional services business. Blackstone’s deployment of Claude across BREIT, BPP and the European logistics platforms will hit the analytical and investor-reporting layers first, well before it touches a Manchester PRS scheme’s leasing operation or a Birmingham office’s facilities team. The same dynamic that is industrialising on one side of CRE is barely visible on the other.
Real estate has stopped being a single industry on a single trajectory. It is two industries that share a name. The week’s news is the moment that becomes impossible to ignore.
THREE REASONS TO READ THE NEWS CAREFULLY
Before going further, three caveats. None of them changes the structural argument. All of them change how to read the announcements themselves.
First: A press release is not an execution. Enterprise software is full of multi-billion-dollar consortium deployments that produced expensive PowerPoints and not much operational change. The pattern is consistent: capital and brand-name partners assemble around a real bottleneck, eighteen months of building, then collision with the operational reality of getting hundreds of mid-market companies to actually change how they work. Roughly 70% of large-enterprise digital transformation programmes miss their stated objectives, and the most common failure mode is precisely the one this consortium structure produces: capital-and-mandate-driven rollouts pushed down through portfolio companies whose operating teams didn’t ask for the system, don’t trust it, and quietly resist it. CRE operations are particularly exposed because the work is local, embodied, and depends on tacit knowledge that headquarters does not have.
Secondly: The model providers and their customers have inverted incentives. The frontier labs make money when their tools are used more: more tokens, more agents in production, more model calls per workflow. The customer makes money when business outcomes are produced with fewer tokens, smaller models where they suffice, and the minimum viable deployment that delivers the result. A deployment company majority-owned by the model provider, staffed by engineers measured partly on AI consumption, has a structural conflict of interest with the customer’s cost-efficiency goal. Forward-deployed engineers sound like service. They are also a sales channel, and a quiet conduit for everything those engineers see while they are inside your operation. There is more to say about this. It will be the subject of next week’s piece.
Thirdly: There is a financial-engineering smell to all this that will not sit comfortably inside an industry rediscovering itself as operational. Real estate has spent the last five years remembering that it is an operational business: the rise of operating partners over fund managers, the mainstreaming of BTR and life sciences and hospitality-led residential, the shift from spreadsheet returns to building-level performance. An AI deployment story sold by Wall Street, packaged with a guaranteed-return wrapper, marketed through portfolio mandates, is going to land badly with the people who actually run buildings. They are right to be cautious. The framework that follows holds regardless of whether any specific consortium succeeds, because the thing commoditising the codifiable layer of CRE is the model itself, available to anyone with an API key and a SKILL.md file. The consortium is downstream of that.
CODIFIABLE AND ACCOUNTABLE
Some knowledge travels in a SKILL.md file. Some doesn’t. The difference is what is being commoditised this week and what isn’t.
Codifiable knowledge is the kind you can write down as a procedure: comp set construction, T-12 normalisation, cap rate triangulation, debt sizing, lease abstraction, IC memo first drafts, valuation models, variance analysis, lender reporting templates. It travels well. It can be packaged, shared, and run by an AI agent with the right context. The MetaProp Labs catalogue is a public library of exactly this kind of knowledge. The new Anthropic-Blackstone and OpenAI-Brookfield deployment firms exist to industrialise the same kind of knowledge inside large portfolios at speed. Codifiable work is directly substitutable.
Non-codifiable knowledge is what Aristotle called phronesis: practical wisdom built case by case, mistake by mistake, consequence by consequence. The investor who senses a deal start to break in a way the spreadsheet does not yet show. The planning consultant who knows which conservation officer in which authority will sympathise with massing exceptions. The retrofit coordinator who knows which contractor on her list can actually deliver the airtightness numbers the model assumes.
Phronesis is not magic, and it is not immune to AI. It is formed through consequence. It comes from seeing real buildings, real tenants, real contractors, real planning committees, real lenders and real mistakes. AI can support this work, document it, search precedent around it, and remove much of the administrative drag. What AI cannot do is become the named person who has lived through enough cases to know when the written procedure is about to fail. Non-codifiable work is indirectly leveraged by AI: the administrative layers around it get stripped away, output rises, and the burden of named accountability sits on fewer humans, more squarely. That accountability becomes scarcer because output is increasing faster than trusted sign-off.
The asymmetry between these two kinds of knowledge is the engine of the bifurcation. Direct substitution on one side, indirect leverage on the other. Where a CRE role sits on that spectrum determines almost everything about its trajectory.
GOOD, BETTER, BEST
Skills, using Anthropic’s Agent Skills methodology, can be deployed at three tiers, and each tier compresses a different layer of work at a different speed.
Good is the public, free, generic skill. The MetaProp Labs catalogue. A SKILL.md file you download and install, designed to work on standard inputs with institutional-standard procedure. It gets a small landlord 80% of the way to institutional-grade thinking on a routine task. Genuinely valuable, historically unavailable. Compresses the floor of the analytical pyramid first and most violently.
Better is the private, firm-tuned skill. The same procedural backbone adapted to a specific firm’s data, conventions, templates, and house view. Built and maintained internally by someone who owns it as an asset. Compresses analyst headcount by 60-80% on the tasks it covers, and creates one new role: the person who builds, curates and improves the skill library. This tier is where mid-tier firms either build a moat or fail to.
Best is the engineered, agentic, system-level deployment. Skills composed into orchestrated workflows with memory, evaluation harnesses, monitoring, exception handling, sub-agents and feedback loops, integrated with the firm’s data substrate, observable enough to be trusted with consequential decisions. This is what the new Anthropic and OpenAI services firms have just been capitalised to build. It is, in practical terms, a moat for the largest sponsors, and a serious build problem for the operationally disciplined mid-tier firms that prefer to construct their own version internally rather than rent it from a consortium.
Three tiers. Different costs, different defensibility, different effects on different parts of the industry.
THE TWO AXES
The framework rests on two axes. Both are jurisdiction-neutral, although the regulatory texture varies: RICS in the UK, the appraisal regime in the US, Sachverständigenwesen in Germany, expert agréé in France. The structural axes hold regardless.
Axis 1: site-specific dependence. How much does the work depend on local, physical, asset-level, tenant-level or regulatory context that cannot be fully reduced to a document set? The answer ranges from “screen only” to “cannot be done off-site”.
Axis 2: named professional accountability. How much of the role’s value comes from a human or institution putting their name, licence, indemnity, balance sheet or regulatory standing behind the answer?
Two axes. Four quadrants. The bifurcation runs through them.
QUADRANT A: HIGH SITE, HIGH ACCOUNTABILITY
Building surveyors, planning consultants, building control, retrofit coordinators, fire engineers, conservation architects, MEP engineers with statutory sign-off, certified energy assessors, technical due diligence professionals. The protected professions of CRE, where the work is anchored to a specific building, a specific authority, and a specific named person who has to stand behind the answer.
This quadrant is the most resilient of the four, and arguably the strongest position in the entire industry. Demand is growing, driven by the largest infrastructure programme in human history: the decarbonisation of the built environment. The UK alone needs to retrofit 28 million homes and over a million commercial buildings to net zero by 2050. Add building safety remediation post-Grenfell, the conversion of redundant office stock to residential, the planning system’s chronic understaffing, the AI data-centre and logistics build-out, the housing crisis. None of this is being automated away.
The formation pipeline in this quadrant is also intact, almost by accident. A young surveyor learns by walking buildings with a senior surveyor. A planning consultant learns by sitting in committee meetings. The apprenticeship is embedded in physical work that AI does not displace, which means phronesis still develops through the channels that have always developed it. AI shows up here as augmentation: better measurement, faster reporting, fewer errors on routine paperwork. The role gets more leveraged. Viability stays.
Career advice for this quadrant: yes, with confidence. Build AI fluency to multiply your output, but do not mistake the AI for the job. The job is still the building, the local context, the regulation, and the named responsibility you sign your name to.
QUADRANT B: HIGH SITE, LOW ACCOUNTABILITY
Property managers, leasing agents, facilities managers, project managers below sign-off level, residential operators, hospitality-led workplace teams, tenant experience leads, asset operators in BTR, life sciences and logistics. The operational backbone of the industry.
This quadrant is resilient but compressing in its administrative layer. AI takes the paperwork fast: lease renewal correspondence, work-order triage, basic tenant queries, scheduling, rent collection chasing, comp gathering. What it leaves alone is the relational, operational, and physical work: walking the asset, talking to the tenant, supervising the contractor, negotiating with the local authority, handling the moment when something goes wrong at 2am. The role gets redefined toward the human-intensity end.
This is where the asymmetric outcome lives. Generic property management businesses compress. Operationally distinctive landlords expand. #HumanIsTheNewLuxury was always pointing here. Hospitality-grade residential, life sciences operations, experiential retail, members’ clubs, curated workplace: these buildings need more people per square foot than today’s mass-market institutional landlords employ, because the per-asset relational density is higher.
Career advice for this quadrant: yes, with the right operator. The serious operational landlords of the next decade win. Generic property management businesses lose. Pick carefully.
QUADRANT C: LOW SITE, HIGH ACCOUNTABILITY
Senior valuation partners signing for secured lending and fund reporting, IC partners with named responsibility, debt structuring at partner level, fund managers with regulatory accountability, named investment recommendation signers, partners signing audited reports. The senior judgement layer of the financial-instrument business.
This is the Pierson Ferdinand quadrant for CRE: partner-heavy, junior-light, AI-supported. Resilient at the top, compressing in the middle, breaking at the bottom. The senior roles survive because the legal and regulatory structures of the industry require named human accountability. As AI floods the world with analytical output, the scarce resource becomes the qualified human willing to take fiduciary responsibility for the answer. That role gets more valuable in the short run.
But the formation pipeline is breaking. The seniors of 2040 were supposed to be formed through the analytical apprenticeship that produced today’s seniors: ten years of comps, models, memos, IC support, supervised exposure to consequential decisions. AI is hollowing out exactly that apprenticeship faster than firms have built a replacement for it. Pierson Ferdinand has decided, openly, that someone else will train the lawyers it eventually hires. Most firms quietly cutting graduate intake and slowing trainee programmes are echoing the same choice without naming it.
Career advice: yes if you are already senior, very risky if you are trying to enter via the traditional pyramid. The traditional pyramid no longer reliably leads to seniority because the rungs have been removed. Entrants need to find one of the firms consciously over-investing in formation against the sector trend, or build seniority through an unconventional path: founder roles, specialist boutiques, family offices, in-house at a sophisticated owner-operator. The era of “join a big house, learn the trade, make partner in twelve years” is closing on this quadrant. It hasn’t fully closed. It is closing fast.
QUADRANT D: LOW SITE, LOW ACCOUNTABILITY
Analyst pools, research, junior IC support, model maintenance, comp pulls, BOV production, deck building, capital markets junior tiers, junior asset management analytics, lease abstraction, draft variance commentary, junior fund accounting, junior valuation modelling. The codifiable middle of the financial-instrument layer.
This is where the pyramid is breaking fastest and most visibly. The MetaProp Labs catalogue is principally aimed here. The new deployment firms are designed to industrialise here. Brynjolfsson, Chandar and Chen at Stanford’s Digital Economy Lab found a 16% relative employment decline for workers aged 22-25 in AI-exposed occupations through 2025, with wages in those roles actually rising. Fewer, more experienced workers doing more. This is not CRE-specific evidence, but it describes exactly the labour-market pattern one would expect if codifiable entry-level cognitive work is being automated first.
There is also a geography to this. Quadrant A is a local moat: the building stays, the planning officer stays, the regulatory regime stays, and the value sits in the named professional embedded in that local market. Quadrant D is a global commodity: a junior CRE analyst’s work is now competing in a global labour market that includes Mumbai, Manila, and any AI agent with an API key. The bifurcation is therefore also a geographic asymmetry. A is locally protected. D is globally exposed.
The career question follows directly. There is no stable long-run position in Quadrant D doing the work as currently structured. Three to five years is the maximum viable time at this altitude before the role’s value has fully migrated to the agents performing it. Drifting in Quadrant D means waking up at 35 with a CV full of work that an agent now does cheaply, instantly, and well enough.
But the quadrant offers three constructive paths out, and the framework should name them clearly.
The first is accountable judgement: build the AI fluency, the relationships, and the domain depth to break into Quadrant C before the formation pipeline closes. The traditional path, now compressed into a shorter window than it was for previous generations, but still real for those who move fast.
The second is relationship-led origination: reposition toward the parts of the financial-instrument layer where the work is fundamentally about sourcing, trust, and client relationships rather than analytical production. Capital raising, deal origination, investor relations, specialist brokerage. These roles sit nominally in low-site territory but are protected by the relational density AI cannot replicate.
The third is AI-enabled workflow ownership: move up the stack from producer to architect. Stop being the person who writes the lease abstract or the BOV; become the person who designs, curates, and continuously improves the firm’s internal skill library, eval sets, monitoring systems, and orchestrated workflows. This is the betterand best tiers of the good/better/best ladder applied inside your own firm. It depends on deep tacit knowledge of how this firm - its data, its templates, its edge cases, its house view - actually operates. That tacit knowledge is its own kind of non-codifiability. It is also, not coincidentally, exactly the work that RIRA’s verifiable cognition layer points toward, and one of the few genuinely scarce roles AI is creating rather than destroying. It deserves more weight than this framework can give it in passing. We will return to it next week.
The framework’s instruction to Quadrant D is therefore not “transition out”. It is “move up, sideways, or up the stack - but do not stay still”. Drifting is the only path with no future.
THE TAM ARITHMETIC
A counter-argument to all of the above is the one a thoughtful reader will raise here: even if the per-role labour content collapses, the market for CRE services is going to expand by 10x as AI brings white-glove services to mass-market clients. Total industry employment grows. The displacement is real but absorbed.
The argument is partially right and substantively wrong. A stylised example makes the point.
Imagine a UK retrofit advisory market with 2,000 specialists today, serving 10,000 assets a year at five-figure fees. Tomorrow, AI-enabled mass-market retrofit advisory could serve a million assets a year at three-figure fees. The market expands by 100x. But the labour intensity per asset has collapsed. If the mass-market service requires one human per 2,000 clients (because most of it is automated), that’s 500 humans serving the million assets. Total advisor headcount: a quarter of what it was. Total market revenue: meaningfully larger.
The pie expanded. The headcount that serves the pie shrank. This pattern shows up in robo-advisory in wealth management, in Squarespace versus the bespoke web design industry, in TurboTax versus high-street tax preparers. Total category spend rose. Total category employment fell.
Worse, the new TAM is rarely captured by the firms that currently serve the old TAM. The mass-market version of strategic asset management for small landlords will not be sold by JLL. It will be sold by a PropTech platform, possibly one that does not yet exist, with a payroll a fraction of the incumbents whose work it commoditises. TAM expansion is real. It does not automatically rescue the incumbent labour model. In most technology transitions, the new demand is captured by new operating models, new distribution channels, and much smaller teams.
The bigger pie is real. It is not the same as more jobs.
WHAT THIS MEANS FOR YOU
Locate yourself accurately on the two axes. Do not guess. Do not be optimistic.
If you are in Quadrant A (surveying, planning, retrofit, building safety, fire engineering, technical due diligence), you are in the strongest position in the industry. Build AI fluency to multiply your output, deepen your local market knowledge, and recognise that what you have is structurally valuable in a way most of your colleagues in other quadrants do not. Do not waste this position by treating it as ordinary.
If you are in Quadrant B (operational asset management, leasing, facilities, residential operations, hospitality-led workplace), pick your operator carefully. The serious operational landlords of the next decade will employ more people per square foot than today’s mass-market institutional ones do, because the per-asset relational density is higher. Generic property management businesses will compress. Operationally distinctive ones will grow.
If you are in Quadrant C (senior fiduciary roles in the financial-instrument layer), your individual role is durable for a decade or more. The problem is what comes next behind you, and whether your firm is doing anything serious about formation. Ask the question. If the answer is “we have outsourced training to AI”, you are working in a firm that is harvesting the last generation of seniors and not replacing it.
If you are in Quadrant D (analyst pools, junior research, model maintenance, deck building), you have a planning horizon of three to five years for the work as currently structured. Three real options: climb into Quadrant C, reposition into Quadrant A or B, or move up the stack into AI-enabled workflow ownership inside your current firm. The longer you drift without choosing one, the harder all three become.
WHAT THIS MEANS FOR FIRMS
The framework changes how a firm should think about itself, particularly if it operates across multiple quadrants. Most large CRE firms do.
The same firm cannot run a single formation model across all four quadrants. A firm with a Quadrant A surveying business and a Quadrant C investment business is, in capability development terms, two firms in one suit. The surveying business should keep training the way it has always trained: real buildings, supervised work, deliberate exposure to the kind of mistakes that build judgement. The investment business needs an explicit redesign of its formation pipeline because the apprenticeship that used to produce its seniors is gone. Treating them as one career path was always a polite fiction. It is now a strategic vulnerability.
Firms straddling Quadrants C and D have a particular problem and a particular opportunity. The problem: the C quadrant depends on a junior pipeline that the D quadrant is industrialising out of existence. The opportunity: cross-subsidising deliberate phronesis development from the firm’s other revenue lines may be one of the few defensible moats in a world where the codifiable analytical layer is commoditised. Pierson Ferdinand has chosen the opposite strategy. Quietly, most large firms are also choosing it without naming the choice. The firms that consciously do the opposite, that over-invest in formation, will produce the seniors of 2040, and will be paid premium prices to provide them to the firms that did not.
Build versus buy on AI deployment is also an open question, and the consortium narrative is trying to close it prematurely. My hypothesis: the operationally disciplined mid-tier players who build their own better-tier capability incrementally, around their own data, with their own engineers, without the financial-engineering overhead and without the model-provider conflict of interest, will compound advantages that the consortium-led buyers will struggle to match. That is a hypothesis. The next 24 months will test it.
The firms that take this path will need the people described in Quadrant D's third option to do the work. Both halves of the prescription are the same prescription, seen from opposite ends of the org chart.
WHAT THIS MEANS FOR THE INDUSTRY
The bifurcation needs to be named. The single-career, single-firm-strategy, single-industry framing currently dominant in CRE commentary is leading people into wrong quadrants by accident. Smart juniors are walking into Quadrant D because that’s where the entry-level jobs are visible, without understanding the floor is dropping. Mid-career professionals are betting on relational-sector expansion to absorb their displacement, without understanding the expansion will be captured by a different category of firm than the one they work in. Firms are running formation programmes designed for an undifferentiated career path that no longer exists.
This is also a policy and institutional question, not just a firm-level one. The IPF, INREV, ULI, BBP, RICS, RIBA, BCO have all set industry conventions before; they could set capability-development conventions now. A modern guild for AI-fluent retrofit professionals, or for phronesis-development in the financial-instrument layer, would be more useful to the next generation than another conference programme. There is more to say about institutional response and state policy, and it deserves its own piece. For now, it is enough to say the collective-action problem is real, the voluntary bodies are well-suited to address it, and most of them are not yet trying.
THE CHOICE
Two industries. One name.
The events of the past week made the split visible at three scales: public CRE skills at the catalogue level, consortium-tier deployment companies at the enterprise level, and a 17.5% return guarantee at the capital level. AI is not hitting the whole industry equally. It is breaking the codifiable apprenticeship on one side of CRE while augmenting the embodied, accountable professions on the other.
So the important career question is now this. Which part of real estate are you actually in?
If your work is codifiable, low-accountability and far from the asset, the floor is dropping. If your work is site-specific, relational, regulated or consequence-bearing, the tools are getting better and your leverage is rising.
The dangerous answer is the comfortable one: “I work in commercial real estate.” That is no longer specific enough.