
THE BLOG
The Workflow You Should Have Burned
The AI product that works is the one you should worry about.
The AI product that works is the one you should worry about. It speeds up the work you do today, shows a return on day one, asks nothing of you, and quietly removes the one thing that would have made you rebuild the work properly. The bill comes later, from a direction you are not watching.
Most of what is being sold to commercial real estate under the AI banner is the same job you already do, done faster. Abstract the lease, but quicker. Reconcile the service charge, but in seconds. Produce the variance pack, but overnight. It sells beautifully, because it slots into how you already work and you can see the saving immediately. And it is, I think, a trap with a very long fuse.
Start with what these products actually do. They take your existing workflow and compress its labour. The workflow itself is left untouched. Nobody asks why you produce that deliverable in that shape, or what the work would look like if you rebuilt it around what the machine can now do. The tool points itself at the artefact you already make and makes it cheaper.
The trouble is that the artefact you already make is a fossil.
You abstract a hundred-page lease into a two-page structured summary because no human can hold a hundred-page lease in their head. That is the constraint the abstract was invented to solve. If the machine can hold the whole lease, and answer any question you put to it directly, the two-page abstract is a buggy-whip: a beautifully made solution to a problem you no longer have. Automating its production is automating the manufacture of something a redesigned workflow might not even want. You have made the horse faster instead of buying the car.
WHY THE GOOD VERSION OF THIS IS THE DANGEROUS ONE
Now, I am not going to tell you that selling the faster horse is a con. It is not. It is often the only sale that works.
Asking a real estate firm to redesign a workflow is asking it to admit the current process is wrong, restructure who does what, swallow the disruption, and trust a supplier with how the work is done rather than just a task. That sale loses to something more urgent every single budget cycle. The “do it with AI” sale wins precisely because it demands nothing: it fits your org chart, it fits your deliverable, it pays back on day one. For the firm selling it, leading with the faster horse is frequently the correct opening move. The question that matters is what happens after the sale.
And there are two firms that make the identical pitch.
One is using speed as a wedge. It lands on “we’ll automate your reporting”, gets inside, learns your workflows, and then uses that position to drive the redesign you would never have bought cold. The other is selling speed as the whole product: bank the saving, never move, sell the same faster horse to the next firm. From the outside, on a website, you cannot tell them apart. They say the same words. The only tell is whether the company has any theory of the rebuilt workflow it is taking you towards, or merely a longer and longer list of things it can speed up. Breadth, oddly, is the giveaway: a firm with a redesign in mind goes narrow and deep on one workflow, because you cannot rethink fifty at once. A firm selling faster horses adds a new horse every quarter.
THE BILL ARRIVES FROM A DIRECTION YOU ARE NOT WATCHING
The comforting assumption is that if you buy the faster horse, you will eventually notice it was the wrong purchase and correct course. I do not think you will. The faster horse is sticky for a cruel reason: it removes the very pain that would have forced you to rethink. The analyst hours that used to hurt, the late nights on the variance pack, the cost that might one day have made you stop and ask whether the whole process was wrong, all of it gets quietly absorbed by the tool. The pain that would have triggered the redesign is gone. So the redesign conversation never happens.
You run a fossilised workflow at ten times the speed, indefinitely. You feel faster, leaner, more modern than the firms around you, and for a good while you genuinely are. You will mistake the speed for transformation, because from the inside they feel the same.
Then one day a competitor who rebuilt the workflow rather than accelerating it does something you simply cannot do at any speed. Not faster reporting: a different capability altogether, one that only exists because they burned the old process and built around what the machine made possible. Your faster horse cannot catch their car, because the race has stopped being about speed. That is when the bill arrives. Years late, from a direction you were not watching, as a capability gap rather than a cost. The faster horse never failed you. That is exactly why it was dangerous. It served you faithfully while quietly foreclosing the thing that would have mattered.
WHAT TO DO WITH THIS BEFORE YOU SIGN
None of this is an argument against buying AI. It is an argument against buying speed on a workflow you should be rebuilding. The two feel identical at the point of purchase and could not be more different five years out.
So before you sign for the next “do X with AI”, ask one question that the demo will not answer for you: is X a workflow I should be redesigning, or merely accelerating? If the honest answer is that the whole process is a relic of constraints the machine has just removed, then speeding it up is the most expensive kind of progress there is, because it feels like winning and it quietly switches off the alarm that would have told you to do the real work.
The firms that win the next decade will be the ones who had the nerve to look at a workflow they had run for thirty years and ask whether it should exist at all. Speed is the consolation prize. The real prize goes to whoever is willing to burn the workflow and build the thing the machine actually makes possible.~
Faster horses are lovely. Just remember what happened to the people who kept breeding them.
Plumbing and Judgement: Where to Spend Your Build Budget
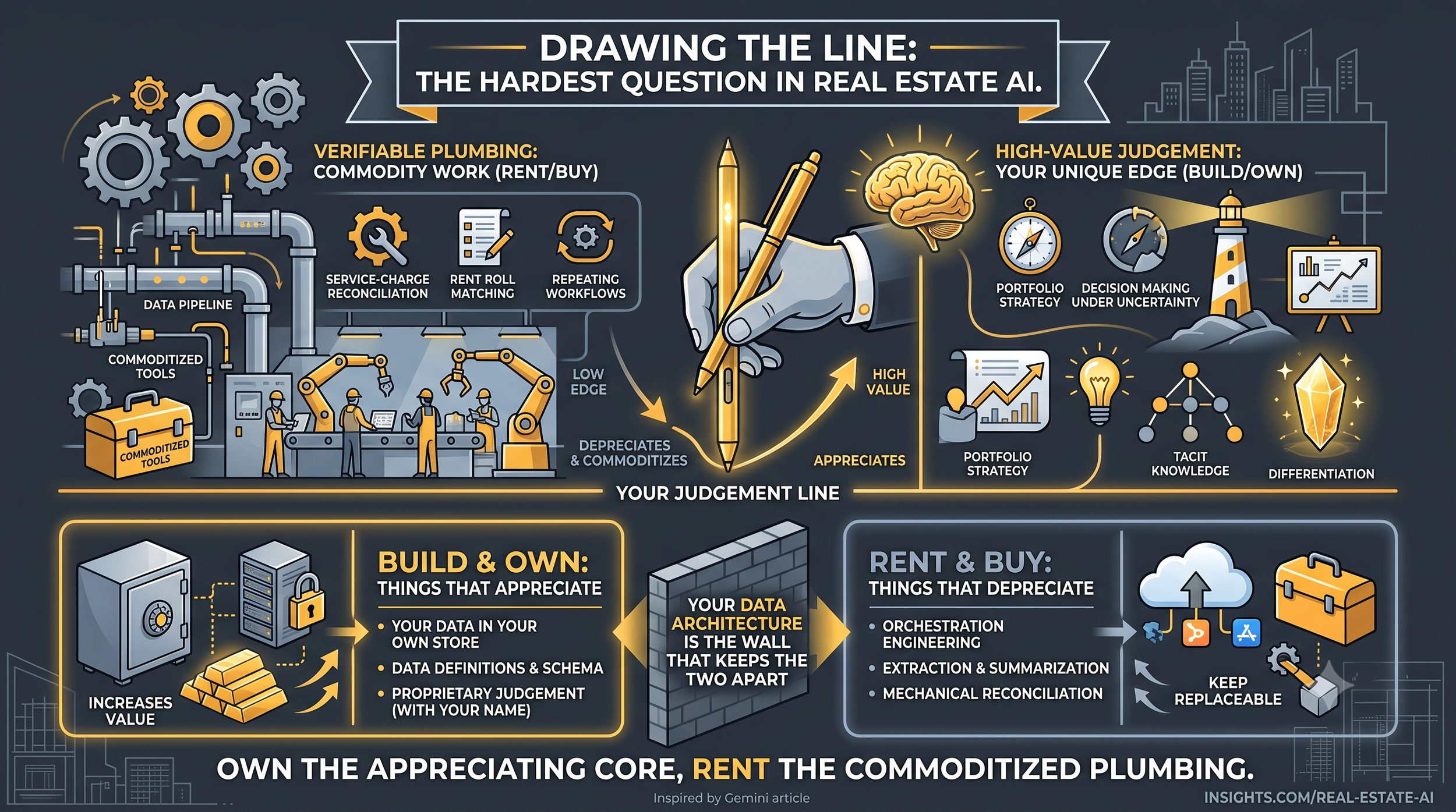
The hardest question in AI for a real estate business is not which tool to buy. It is which work to keep.
The hardest question in AI for a real estate business is not which tool to buy. It is which work to keep. Get the line right between the two and dependence becomes safe. Get it wrong and you automate away the very thing that made you worth hiring.
For years the received wisdom in real estate technology was simple: don’t build, buy. Someone else will amortise the engineering across a hundred customers and sell it to you for a fraction of what it would cost to make. That wisdom was correct for fifteen years. It has quietly stopped being correct, and the firms that have not noticed are about to make expensive mistakes in both directions: building what they should rent, renting what they should build.
Let me start with the distinction that does all the work.
Every workflow in your business breaks into two kinds of work. There is plumbing: the verifiable, mechanical work where the output either reconciles or it doesn’t. Did the service-charge reconciliation tie out? Does the rent roll match the leases? You can check the answer cheaply and mechanically, and so can anyone else. Then there is judgement: the work of deciding what to do under uncertainty, where the line falls, what a thing means. Two experienced asset managers look at the same portfolio and reach different reads, and neither can fully show their working, because the working is partly tacit and partly theirs.
Plumbing and judgement behave in opposite ways, and that is the key to the whole thing.
Plumbing commoditises. The way you reconcile a service charge is roughly the way everyone reconciles a service charge, which is exactly why a supplier can build it once and sell it to the entire market. There is no edge in it. There never was. A reconciliation done perfectly is table stakes, and being unusually good at it wins you nothing, because your competitor’s reconciliation is identical to yours.
Judgement does the reverse. As the plumbing around it gets automated and cheap, the judgement that remains becomes more valuable, because it is now the whole of your differentiation and everyone’s commodity layer looks the same. The residue concentrates. What is left when the routine 80% has been automated is a smaller share of the work and a larger share of the value.
THE TRAP DRESSED AS THE SOLUTION
This is where firms walk straight into trouble.
Working out what to automate is itself a pieece of judgement, and it is different for every firm. The decomposition of your own workflow, which parts are plumbing you should hand away and which parts are the judgement that distinguishes you, is one of the most firm-specific things you own. It is partly constituted by what you have decided your edge actually is.
So a supplier can do your plumbing for you, gladly, and you should let them. A supplier cannot do your deconstruction for you, because the answer depends on what makes your firm your firm, and they do not know that and cannot. A vendor who sells you a ready-made answer to “which parts of your work are the valuable parts” is selling the identical answer to every other customer. At which point it has stopped being judgement at all.
The vendors will not put it this way. The piitch is always the friendly one: skip the hard part, we’ll handle the structuring, you don’t need a data project. And accepting that pitch is the precise act of handing them the layer you most needed to keep. The convenience and the lock-in come in the same box. You cannot buy one without the other unless you deliberately keep the judgement work inside your own walls.
A SIMPLE MAP FOR WHERE THE BUDGET GOES
None of this means build everything. Building everything is how a real estate firm turns itself into a mediocre software company, and the cost of that is brutal. The discipline is narrower and more useful than “build” or “buy”. It is a line, drawn through your own operation, with most of the surface area on the rent side and the small valuable core on the build side.
Reach for this when you are deciding:
- Own the things that appreciate and cannot be got back. Your data, in your own store, under your own keys. The model of what your data means: the schema, the definitions, the way your messy reality resolves into structure, wherever that meaning is part of your edge. The judgement that carries your name and your balance sheet behind it. These get more valuable as the models improve, and once given away they cannot be repatriated. Build and hold them.
- Rent the things that depreciate and commoditise. The orchestration engineering. The extraction. The reconciliation. The summarising. All the verifiable plumbing that nobody’s edge ever depended on. Buy it freely, and keep it deliberately replaceable, so no single supplier can ever turn the screws.
The unifying rule is one sentence. Own what appreciates and cannot be repatriated; rent what depreciates and commoditises; and treat your data architecture as the wall that keeps the two apart.
A CAVEAT THAT MATTERS
Part of my argument for building more than you used to is that the cost of building has fallen hard. The claim is that a domain expert with these tools can now produce in days what once took a team a quarter. I believe that is directionally true. I also want to flag it as the place this argument is softest, because “I built a working version in an afternoon” and “this runs in production at institutional reliability, verified and governed” are separated by exactly the gap where most enterprise AI projects go to die. The cost of specifying the cognition has collapsed. The cost of the production engineering and the verification harness around it has barely moved. So when I say build, I mean build the valuable core and resource the unglamorous reliability work properly. The firm that hears “building is cheap now” and skips the second half will have a brilliant demo and nothing it can trust.
The decision was never really build or buy. It was always: what is plumbing, and what is judgement? Answer that honestly, for your own firm, and the rest falls out. Answer it lazily, or let a vendor answer it for you, and you will rent your judgement and build your plumbing, which is the most expensive way to get an AI strategy exactly backwards.
So draw the line yourself. Nobody can draw it for you. That, it turns out, is the first piece of judgement the whole thing depends on.
The Toll and the Amputation
Why AI lock-in is no longer about the cost of leaving, but the capability you lose when you do
Every commercial real estate firm is about to become dependent on AI suppliers it does not control. That has always been true of technology. What has changed is the kind of dependence, and the difference decides whether you keep your edge or hand it over without noticing.
I have spent a decade telling this industry that the question with technology is never whether, only how and how fast. On dependence I want to change the emphasis. The how-fast matters less than the what-kind. Because there are two kinds of lock-in, and most property people are bracing for the wrong one.
A note on form before I start. I usually write long. For the next few weeks I am doing something deliberately different: four short pieces, one idea each, on the single shift I think matters most for where this industry is heading. This is the first. They sit underneath the redesign argument I keep coming back to: that the work is to rebuild what AI makes possible, not to automate the thing you already do. Consider this the dependence corner of that map. I will break off to write about whatever the week throws up, so they will arrive as an occasional series rather than a march.
You already know the old kind. You have lived inside it for years. You pick a property management system, you pour your data into it, you train your people on it, and five years later moving to a competitor is a bet-the-operation migration that nobody wants to sign off. The cost of leaving is enormous. Everyone knows it is enormous. That knowledge is the lock-in.
Call that the toll. It is expensive to leave, but you leave intact. Your knowledge of how to run your buildings walks out of the door with you, mostly in the heads of your people and in the processes you documented. The new system is a pain to stand up. Six months later you are running again, and you are the same firm you were before, just on different rails.
AI lock-in is a different animal, and the difference is the whole argument.
When an AI system runs a workflow for you for three years, it learns. It learns the patterns in your data, the exceptions your people make, the awkward cases and how you handle them, the thousand small judgements that constitute how your firm actually does the work. That learning accretes inside the supplier’s system. It was generated by your usage, on your data, about your portfolio. And it was never in a form you possessed.
So when you try to leave, you can take your data. You cannot take the knowledge. The knowledge was constituted somewhere else, as a by-product of you using the thing. You walk away having forgotten how to do the work, because the system did it for you and the institutional memory of how now lives in a methodology you do not own.
The toll is a cost you pay to leave. The amputation is a capability you lose by leaving.
That is the distinction, and once you see it you cannot unsee it. Old lock-in raised your exit cost. AI lock-in degrades your capability. One is a toll booth on the way out. The other removes something you needed to keep.
WHY THIS FEELS WORSE THAN IT IS, AND WORSE IN ONE PLACE THAN YOU THINK
Now let me argue against myself for a moment, because there is a twist.
In one respect the old lock-in was the more brutal of the two. Ripping out a system of record really was a multi-year nightmare, and plenty of firms started those migrations and never finished. AI dependency, by contrast, sits on top of a layer of standards and protocols that is getting cheaper and more interchangeable every quarter. The plumbing underneath is becoming more swappable over time, not less. So the instinct to fear AI dependence across the board is, in large part, misplaced. Much of it is loosening on its own.
The genuinely new danger is narrow and specific. It is the knowledge layer. It is the methodology capture that was never extractable in the first place. Everything else (the integrations, the pipes, the orchestration engineering) is commoditising, and you should treat it as replaceable infrastructure and stop worrying about it. Spend the worry where it belongs.
The mistake I see firms making is the opposite. They over-defend the plumbing, because plumbing is visible and has a price tag, and they under-defend the knowledge, because knowledge is invisible and arrives as a problem years later. They will negotiate hard on the licence fee and sign away, in the same contract and without reading it, the thing that actually matters.
THE ONE QUESTION THAT SORTS IT
You are going to be dependent. I am going to be dependent. Everyone building anything serious will depend on suppliers they do not own, and that is fine, and pretending otherwise is a fantasy. The real work is sorting the safe dependence from the dangerous kind, and there is one question that does the sorting:
Is the thing you depend on also the thing capturing what makes you you?
Where your dependence runs through commoditising infrastructure, with many suppliers, all swappable, none of them accreting your edge, depend away at any depth you like. It costs you nothing, because nobody’s competitive advantage ever lived in the plumbing. But where your dependence runs through a system that is quietly learning the judgement that distinguishes your firm, you are handing over the family silver one quarterly usage report at a time, and the invoice for that arrives late, as competitive disadvantage, long after the decision that caused it.
The toll you can always pay. The amputation you cannot undo.
So before you sign the next “do it with AI” contract, do not ask what it costs. Ask what it learns, where that learning lives, and whether you could ever get it back. If the answer is it learns your edge, it keeps it, and no you cannot, then that is no supplier at all. It is a slow transfer of the one thing you most needed to own. Read the contract with that question in hand. Most people won’t. You can.
The Third Letter
Why AI's losses are easy to count, and its gains almost impossible to imagine.
An AI Art company just announced a body scanner. Almost nobody in the AI debate had that on a roadmap. Which says something about the future: it isn’t hard to predict because it’s uncertain. It’s hard because it stays unimaginable until somebody imagines it.
So this week I’m going to ask a machine to imagine the future of our industry. It fails first, in the most instructive way possible. Then I force it to do better. The gap between its two answers is the whole argument.
This week Midjourney announced a medical division. Yes, the text-to-image people, the ones who turn ‘a cat in the style of Vermeer’ into a picture. Their first announced hardware project is a full-body ultrasound scanner. You step into a shallow pool, sink through a ring of ultrasound-on-chip sensors, described, wonderfully, as being surrounded by tiny echolocating dolphins, and sixty seconds later walk out with a 3D map of your insides. And they plan to open the first one in a San Francisco spa in 2027. Hot tubs, saunas, cold plunges, and a machine that reads your body.
Put aside whether it works. It isn’t cleared for diagnosis, barely anyone has been through it, and there’s a regulatory mountain between here and a working medical product. None of that is the point. The point is that almost nobody in mainstream AI commentary had this on the map. Not the productivity analysts, not the slide-deck futurists, not most of the people confidently narrating the next decade. An image-generation startup building body-scanning hardware wasn’t a long shot everyone rated too low. It was absent. It sat outside the entire space of things anyone thought to forecast.
WE CAN COUNT THE LOSSES. WE’RE BLIND TO THE GAINS.
The public has soured on AI, and it isn’t stupidity that did it. The destruction is concrete. You can count it. Dario Amodei, founder of Anthropic, makers of Claude, says half of entry-level knowledge jobs could go within five years, and whatever you make of the number, you can picture it: a junior analyst’s tasks, automated; a whole rung of the career ladder, gone. It has a shape.
The creation has no shape. The jobs AI will invent, the categories it will open, the work that pays people’s mortgages in 2035: none of it can be counted, because none of it exists yet to count. So the debate is a rigged fight. A vivid, quantified fear against a vague, unquantifiable hope. Concrete wins every time. Of course sentiment curdled.
And that asymmetry has split the commentary into three camps, only one of which is being honest with you.
The first camp says everything will be fine. These are the tech leaders who spent years insisting AI would change everything, otherwise why pour a trillion a year into it, and who then went quiet on disruption the precise moment the public turned hostile. Now the message has softened to reassurance: new tools, new productivity, nothing to fear, the jobs will sort themselves out. It’s a comfortable story and it is almost certainly false.
The second camp says it’s all catastrophe: mass unemployment, civilisational write-off, the machines win and we lose. Also a story, also too clean, and just as useless because it offers nowhere to stand and nothing to do.
The third camp says something harder, and it’s where I am. Yes, the change is enormous. Yes, much of it will be extraordinary. And no, everything will not be fine. A great deal will change, real people will be really hurt, and amazing things will happen, all at once, and you have to hold all three in your head without letting any one of them cancel the others. That’s the uncomfortable middle. It doesn’t trend on either side of the argument because it doesn’t comfort anyone.
Watch what separates the honest from the rest, because it’s a tell. Amodei kept warning, loudly, after it became unfashionable, precisely so society can prepare: protect the people who’ll be hurt, build the mitigations, lean into the upside with eyes open. There’s a world of difference between predicting destruction to frighten and predicting destruction to mobilise. He’s doing the second. The boosters who fell silent were never doing either, honestly. We must protect the downside as we lean into the upside, and you cannot do the first if you’ve talked yourself into believing there is no downside.
This is not a new pattern, and that’s exactly why I trust it. Ask the handloom weavers of the early nineteenth century. They looked at the power loom and concluded they were finished, and they were right: within a generation a skilled, proud, well-paid trade was gone, and the men who had it died poorer and angrier than they began. The economists looked at the same machine and concluded that employment would recover and the country would grow vastly richer, and they were right too. Both were right. The catch is in the word ‘generation’. The aggregate healed over fifty years; the individual weaver had perhaps fifteen working years left and spent them watching his living evaporate. ‘The system adjusts’ is true and it is the coldest possible comfort to the person whose decade is the one that breaks.
You can run the same tape forward through almost every wave since. The Luddites were not wrong about their own looms; they were wrong only about the long-run aggregate, which is no help at all if you’re inside the short run. By 1950 something like one in thirteen working women in America was a telephone switchboard operator. Automatic switching erased the job almost entirely. The gains were real and the losses were real and they landed on different people at different times, and pretending otherwise is the thing that makes the public stop trusting you.
So hold the two thoughts. Protect people: not as a slogan, as actual policy, retraining, redistribution, a genuine reckoning with who carries the cost. And stay open to a creation side that is every bit as real as the destruction, even though we can’t yet see its face. The boosters can’t see the losses. The doomers can’t see the gains. The honest position is the only one looking at both columns at once.
Which brings me back to Midjourney. The scanner isn’t proof that this particular product will work. It’s proof of something more useful: the creation column has entries we don’t yet know how to name. Nobody could see this one coming, and it arrived anyway, enormous and strange and out of nowhere. That’s the gain side made concrete, for once. The trouble is it only became visible after it existed.
So the question that has been nagging me is whether we can drag the next one into view before it arrives. Can we use these models to help us guess at the third letter? Let me try.
THE MACHINE FAILS FIRST. FLUENTLY.
Prediction is very difficult, especially about the future. Usually attributed to Niels Bohr, though, fittingly for a line about uncertainty, its own origin is uncertain. But our problem runs deeper than prediction. We can’t imagine.
Real estate has its own version of this blindness. Ask people what AI will do to the industry and almost every answer removes friction from today’s work: faster leasing, cleaner data rooms, automated valuation, instant IC papers, predictive maintenance. Useful. Eventually transformative. But still recognisably the same industry doing the same things, quicker. The harder question isn’t what AI subtracts from real estate. It’s what AI lets real estate become.
So I ran the obvious experiment. I asked a frontier model: you’re a CRE professional in 2035, write a letter to your 2026 self about all the amazing things that have happened. Here’s what came back, lightly trimmed:
“Dear 2026 me,
You won’t believe how much easier the work has become. I haven’t built a lease abstract by hand in years: the system reads every document the moment it lands. Due diligence that ate three weeks now takes an afternoon. Buildings basically run themselves, every asset with a digital twin that spots the failing chiller before the tenant feels it. Leasing is faster, pricing adjusts to demand, valuation is real-time. The job is the same job, just with the friction taken out. You’re going to love how much time you get back.”
Read it back and the problem surfaces. Every sentence is plausible. Every sentence is also completely imaginable from where you sit today. There’s nothing in there you couldn’t put on a slide this afternoon. Digital twins, agentic due diligence, dynamic pricing, real-time valuation. It’s the entire efficiency deck, in a warm voice.
And the tell is right there, in the machine’s own words: the job is the same job, just with the friction taken out. It described a decade of change in which nothing was created. Things only got faster. No new category. No new thing a building does. No job that didn’t exist before.
Don’t dismiss it, though. This isn’t the failure. It’s the floor.
Everything in that letter is leading-edge today and will be utterly ordinary by 2035. It’s the homework, not the future. And if you nodded along reading it, look at what you just did. You imagined the subtractive future without breaking a sweat. That’s the trap. The friction-removal story is the easy half of the ledger, and the machine handed it over in elegant prose precisely because it’s the half we can all already see.
NOW FORCE IT OFF THE TREND LINE.
So I changed the rules. Write it again.
Every development has to be one that would have sounded absurd in 2026, the way ‘AI Art company builds a body scanner’ sounds absurd. No efficiency gains. No faster versions of today. Only new categories. Tell me the part of the job that didn’t exist as a job, and the thing my 2026 self would refuse to believe.
“Dear 2026 me,
Stop thinking about your job. It’s the wrong unit. What changed is what a building is*, and therefore what we’re for.*
We don’t really lease space any more. We underwrite outcomes. A logistics tenant doesn’t sign for 200,000 square feet at a rent. They contract for guaranteed throughput, so many units shipped per day at a committed cost, and the building, the robotics, the energy contract and the labour AI are bundled into one number we’re on the hook for. The rent roll isn’t a list of rents. It’s a portfolio of performance guarantees. Half my job is pricing operational risk, which in your day was the tenant’s problem and nobody else’s.
The buildings negotiate with each other. Not as a figure of speech. Every asset runs an agent that knows its own spare capacity, power, cooling, parking, the embodied carbon it has banked, and trades it with the buildings around it. My portfolio sells off-peak cooling to the data centre three blocks over and buys their waste heat in winter. There’s a live market in adjacency. Location stopped being a fixed attribute. It’s a trading position now. We used to call this facilities management. Now it’s a trading desk.
Vacancy stopped being a cost and became a feedstock. An empty floor is raw material. The moment it’s vacant the building reconfigures it into whatever the demand-map says the neighbourhood is short of that month: compute, cold storage, clinical capacity, a film stage, a quiet room people rent by the minute. Space stopped having a use and started having a state that updates. Signing a ten-year lease to fix a use-class for a decade now sounds as strange to me as renting a single web page for ten years would sound to you.
And the one you genuinely couldn’t have pictured: a building carries part of its occupants’ cognition. The space holds the context of the work happening inside it and hands it to whoever walks in. The room joins the meeting instead of just housing it. We don’t sell square footage. We sell a place that thinks alongside you. Turns out that was the product all along. We just couldn’t build it until intelligence got cheap enough to pour into the walls.
You spent years arguing space was becoming a service. You were directionally right, and you under-shot. Space became an agent. Keep imagining. You’re not wrong often enough.”
Now that is a different letter. Every item passes the Midjourney test. Each one would read as a category error today. We don’t lease space, we underwrite outcomes. Buildings running a trading desk for their own externalities. Vacancy as feedstock. The room that thinks alongside you. None of it is a faster version of now. All of it is a different answer to the question of what this industry is even for.
Be clear-eyed about what just happened, though. The machine didn’t conjure this from nothing. It recombined things that already exist, outcome-based contracting, energy trading, carbon markets, agentic AI, and frankly my own #SpaceAsAService thesis, and shoved them past the point where I’d have politely stopped. That’s not prophecy. Most of it won’t happen, or won’t happen like that. Its job was never to be right. Its job was to be imaginable: to prove the creation column has entries, even when we can’t yet read them.
THE THIRD LETTER
So does the trick still work? Yes, but only against resistance. Left alone, the model fails fluently. It hands you the friction-removal letter and you’d have to be paying attention to spot that it told you nothing new. Forced off the trend line, it earns its keep. It won’t predict the future for you. It’ll push your own ideas past where your nerve gives out.
Which leaves me both optimistic and humble. There are really three letters. The first is the future that’s merely late: today’s edge, tomorrow’s baseline. The second is the absurd-sounding one, reachable only when you force the recombination. And the third? The third letter is the real 2035, and neither I nor the machine can write it, because its ingredients don’t exist to recombine yet. Exactly as nobody in 2021 could have written ‘AI art company builds a dolphin spa that scans your body.’
Remember where we’re heading. If current scaling trends hold, the leading models of 2030 could be trained on something like ten thousand times the compute behind today’s frontier. That’s Epoch AI’s central projection, and the International AI Safety Report puts the same growth rate at the same place. Call it a thousandfold and you’re being conservative. Whether it arrives smoothly or in fits and starts, it is my belief that this is the single most under-weighted fact in our industry. The first letter is what that buys when it matures. The second is what it buys once intelligence is cheap enough to live in the walls. The third is everything those two still can’t reach. And there will be a third letter. There always is.
For our industry the question underneath all this is brutally simple. Does a building stay inert capital stock, or does it become an operating system? Does location stay a fixed advantage, or turn into a network position that trades? Does vacancy stay lost income, or become programmable capacity? Right now we are pouring AI into the first half of each of those sentences and barely glancing at the second. The efficiency deck is the first half. The second half is where the industry actually changes.
That’s why I’m optimistic. The losses are real, and we owe it to people to protect them on the way through. The gains are real too, even though their faces haven’t arrived yet. The job was never to forecast. The job is to keep imagining. And to treat ‘that sounds absurd’ as a signal, not a verdict.
So go and write your own second letter this week. Force the machine off the trend line. See what it drags into view. Then remember there’s a third one coming that none of us can write yet.
That’s the one I’m waiting for.
The Office That Earns Its Rent
Buildings that can prove they deliver for occupiers

Smart buildings optimise. Causal buildings prove. The next office advantage is not a smarter thermostat or a slicker tenant app: it is a building engineered to prove, causally, what it does for the people and businesses inside it. The capital that could build it is not yet pointed at it, and the players racing into AI cannot own it, which is exactly why it is still a moat.
There is a debate running through commercial real estate about how to wire up a building’s data: sensors or business systems, one cleaned central store or a layer over what you already have. I have sat with it for a while and come to think it is the wrong argument, or at best a second-order one. In a market culling offices that cannot justify their rent, the question is not how you plumb the data. It is what you are trying to build with it.
The short version. The industry is arguing about data architecture when it should be asking what the data is for. A building set up properly for AI can answer three escalating questions: what is happening, why it is happening and what happens if I intervene, and what to do about it. The hard part is causation, and it is half-solved already: physics-based control handles the engineering side and is now buyable; the commercial side, whether the building causally drives rent and retention, is the prize, and it is a portfolio capability that institutions are uniquely placed to own. Incumbents do not build it because their incentives forbid it, and even the new AI consortia arming the industry leave it untouched. The model is a commodity. The causal substrate is the moat, and it is most valuable retrofitted into the ageing offices fighting for their lives.
Two years ago I argued that real estate’s future was to become a Maven: not a passive provider of space but an active facilitator of human success, judged on outcomes: productivity, wellbeing, the things people actually come to an office for. I stand by every word. But a Maven makes a promise it has had no way to keep. It claims to improve the people inside it; ask it to prove that, causally, to a tenant weighing a renewal or an investor setting a price, and it goes quiet. The causal building is how the Maven keeps its promise.
THE ARGUMENT ABOUT PLUMBING
The current debate is narrower, and a long way from that promise. Strip away the jargon and it is an argument about plumbing. One camp wants a building’s intelligence to come from its own sensors and equipment: the data at the ‘edge’. Another wants it wired together from the business systems you already run, the leasing and accounting and management software: the ‘APIs at the core’. Beneath that sits a second quarrel about whether you haul everything into one clean central store or leave it where it lives and build over the top.
Plumbing matters. But choosing a side in it does not, by itself, give you intelligence, and it is downstream of a better question: what would a building look like if it were set up, deliberately, to produce causal evidence about what it does to the people inside it, and to act on that evidence?
Call it the causal building. Not a ‘smart’ building, the connected-automated-efficient-pleasant thing the industry has promised for thirty years and the best new towers now deliver. A building that works as an evidence engine. It knows not only what is happening and what will happen, but why, and what changes if it acts. And it can prove it to an audit committee.
THREE QUESTIONS A BUILDING SHOULD ANSWER
There are three kinds of AI doing the rounds, and they are not interchangeable. They make escalating demands, and a building set up properly answers all three:
Analytical AI answers what is happening, and what will happen. Prediction, anomaly detection, the energy curve. This is the commodity layer.
Causal AI answers why it is happening, and what happens if I change something.Explanation and counterfactual. This is where the money is.
Generative AI answers given all that, what should we do, and can you do it. The interface, and the hands.
Almost every ‘smart building’ on the market answers only the first. It senses, predicts and optimises beautifully, and stops there. The value, and the difficulty, climbs with each step. Causation is the one the industry has skipped.
THE CAUSAL PROBLEM IS HALF-SOLVED
Here is the good news, because the causal question sounds impossibly demanding and is not. It splits in two.
The engineering half, energy and comfort and the behaviour of the plant, is governed by physics, and a physics model is already a causal model. It knows that opening the damper moves the air without having to run an experiment to find out. Correlation has to be taught; physics comes knowing. Troy Harvey’s PassiveLogic is the clearest example: a physics-based digital twin that runs autonomous control at the edge and infers what it cannot directly measure. You can buy a version of this, or build a generic one with decades-old model-predictive control. Either way you specify engineering causality. You do not invent it.
The commercial half is the prize, and no physics will help you. Does comfort causally lift renewal? Does a floor’s configuration causally raise the tenant’s own productivity, and so their willingness to pay? These are questions of cause and effect in human behaviour, and they need experiments: matched floors, staggered rollouts, the boring discipline of logging every intervention and its result. The methods are standard econometrics. What is scarce is the will to use them.
In practice it looks like product experimentation pointed at space. One floor runs an altered lighting or thermal regime while a matched floor holds steady; an amenity change goes to one building and not its twin; every intervention is logged against the things that actually move money, renewal risk, utilisation, complaints, helpdesk tickets, sentiment. The aim is not laboratory perfection. It is disciplined comparison, repeated across enough assets to learn faster than the market.
A single building cannot run good experiments; a portfolio can. Scale, which usually buys you nothing but procurement leverage, here buys a causal-learning advantage no rival can copy without the same fleet. Better still, the autonomous control that delivers the engineering half is the very instrument that makes the commercial half feasible: a building that can hold a variable exactly, or vary it cleanly across two floors, is a controllable experiment. The thing everyone wants for energy is the thing that lets you finally answer the questions that move NOI.
There is a red line, and it is not optional. This works at the level of the floor, the cohort, the tenant and the portfolio. It does not work, and must never work, at the level of the named employee. The moment the causal building becomes workplace surveillance dressed as building intelligence it is unlettable, and rightly so. The trust architecture matters as much as the data architecture: consent, aggregation, governance.
WHY JP MORGAN STOPPED SHORT
If this is so valuable, why is it not being done? The answer is structural.
The brokers are disqualified by their own model. JLL has Hank, a genuinely capable autonomous-HVAC platform; CBRE runs Smart FM across a billion square feet with its Nexus data platform and Ellis AI assistant. Both are excellent at the analytical and automation layers, and their research arms make causal-sounding claims all day: the green premium, the flight to quality, the amenity that lifts rent. But that is market-level correlation sold as advice, the average across everyone’s buildings. It is not an owned, instrumented engine that proves what this building does to these tenants. And a broker has little reason to build that: the deep, asset-specific version is the client’s moat rather than its own, sits on an asset it may lose at the next tender, and needs commercial data owners guard. The broker’s economics reward the opposite, a shallow benchmark spread across a billion square feet. Useful, but not the same thing.
The more telling case is JPMorgan’s new headquarters at 270 Park Avenue: thousands of sensors, AI trimming light and temperature in real time, solar shades wired to the HVAC, all-electric and net-zero. JPM owns it, occupies it, and holds every scrap of commercial and workforce data needed to close the causal loop. A caveat: I am reading this from the outside, from what is public, so take it as inference, not fact. JPMorgan may do more behind closed doors than it says. But the public story is sustainability, intelligence and prestige, not causal proof of how the building changes the people and the business inside it, and a firm that had built the evidence engine would be telling that story. One of the most expensive and ambitious corporate headquarters ever built, and on the public record it still cannot show you whether the building earns its keep. It built the most advanced energy-and-experience building on earth, not the most advanced evidence building, because the causal-commercial question is nobody’s job. Buildings get commissioned against carbon, air quality, daylight, amenity and cost: legible, certifiable, defensible. Causal social science on your own workforce is messy and politically fraught, so even a firm with near infinite money defaults to the certifiable.
The gap, then, is not technology. The apex buildings are stuffed with technology. It is framing and incentive. The industry defines a smart building as connected and efficient and pleasant, and operates inside that definition brilliantly. The causal building asks a different question, and the brokers’ economics and the occupiers’ incentives both point away from it.
AI DID NOT GIVE YOU THE ANSWER
A fair challenge: hasn’t generative AI changed all this? It has, in one half and not the other.
Much of the optimisation was always possible and shamefully neglected; AI just removes the alibi by making it cheap. What is genuinely new is that frontier models can finally read the commercial half of the building, the leases and contracts and reports that were locked in PDFs, which is what lets you join how a building behaves to what it earns. That, plus agents that can act rather than merely build dashboards, is the real change.
But the causal core is the one thing AI does not hand you. A frontier model is the most articulate pattern-matcher ever built. Ask it why your renewals are sliding and it will give you a fluent, confident answer stitched together from correlation. Fluent is not the same as right. That is ‘workslop’ at the level of analysis. Causation comes from physics or from experiments, never from the model alone. AI is the connective tissue and the interface. It is necessary, and nowhere near sufficient.
The people building the biggest AI bets agree. In May, Anthropic launched a $1.5bn venture with Blackstone, Hellman & Friedman and Goldman Sachs to embed engineers inside portfolio companies and rebuild their workflows, with real estate named as a target. Days later OpenAI stood up a $4bn-plus ‘Deployment Company’ to do much the same. Their pitch is that the model alone changes nothing: the value is in the deployment and the redesign around it. They are right, and proving my point at scale. They will hand the whole industry the commodity workflow layer. But their incentive is to sell workflow transformation, not to build you an owner-controlled evidence substrate for your own portfolio, and you should think hard before renting your operational intelligence from a consortium whose anchor is one of the largest landlords on the planet. Rent the model. Own the substrate.
WHO THIS IS ACTUALLY FOR
It is not for everyone, and the reason is the holding period. Offices change hands every five to ten years on average, and the commercial-causal payoff matures over a lease cycle. If you are a three-year value-add buyer, do the energy layer that pays for itself and stop there.
For everyone else it stands up. It is built for the long-capital owners and the owner-occupiers, the pension funds and insurers and sovereign wealth and the firms that sit in their own buildings for decades: the natural owners of prime office, not a fringe. The right unit of return is not the building but the portfolio capability, which compounds across assets and outlives any single hold. It rests on a hypothesis, and I will flag it as one: that the market will learn to price causal proof of performance the way it learned to price energy, where green moved from unpriced to a measurable premium with a brown discount for the laggards. I think that bet is sound, and the early mover helps set the price rather than pay it.
If this were in everyone’s interest it would already be commoditised and worth nothing. It is precisely because the short-hold majority cannot justify it, and the brokers err away from it, that the long-hold owner who acts captures something durable. The misalignment is the moat.
And it is not only for new towers; the opposite is true. A shiny headquarters lets on prestige and need not prove it earns its rent. It is the commodity 1990s and 2000s office, staring down obsolescence, that most needs to prove its worth, and the substrate retrofits into exactly that building as a defence against it emptying. The hardest case is where the thesis pays best.
WHAT GREAT LOOKS LIKE
The perfect office is not the one with the most sensors or the cleverest app. It is the one that can prove what it does to the people inside it, built on a data substrate you own, with the frontier model as a commodity bolted on top and swapped out whenever a better one arrives. This is the Maven I described two years ago, finally handed the one thing it lacked: the means to prove itself. It is #SpaceAsAService with the evidence attached, and it is where ‘Human is the New Luxury’ stops being a slogan and becomes a number you can defend.
The technology is here. The methods are mature. The excuses are running out. What is missing is the will to treat a building as something that learns, and whether your buildings ever do is entirely down to you.