You need to prompt with skill
No matter who you are, quality prompting has a high ROI
A Prompting Framework for CRE Professionals:
In the first part of this series we looked at RIRA- a strategy-to-execution framework for rebundling value creation in commercial real estate under conditions where AI materially changes the unit economics of analysis and content production. And last week we looked at ‘The CRE Automation Matrix Framework’ - a tool for understanding where value is moving to, what to automate, and how. This week we introduce ‘A Prompting Framework for CRE Professionals’, showing how effective prompting is a repertoire matched to domain expertise, AI fluency and task mode.
Together these frameworks form a set of foundational tools for maximising the impact, and leverage, of AI on any business.
THE EVIDENCE
Anthropic, makers of the frontier AI model Claude recently published their fourth ‘Economic index Report’, in which they show that people who can articulate complex, nuanced requirements in a prompt get complex, nuanced outputs. AI amplifies existing expertise rather than substituting for it. The ROI gap between a team that knows how to prompt well and one that doesn’t is enormous.
So if you have domain expertise, and prompting expertise, you will gain the most from current AI.
What This Framework Is
The ‘Prompting Framework for CRE Professionals’ is a practical framework for choosing how to prompt based on two realities of professional work:
(1) your domain expertise is relative to the problem you’re facing (you can be an “expert” in offices and a “novice” in data centres)
(2) your task is either Discovery (sense-making, shaping the problem, exploring options) or Execution (producing a deliverable under constraints).
The framework maps these two variables into four prompting modes - A, B, C, and D - and adds an expert loop (“Mode Switching”) that deliberately alternates between divergent analysis and convergent drafting to produce better work with fewer avoidable errors.
Why it matters: the Strategic Problem AND What Goes Wrong Without It
Most AI misuse in commercial real estate is not “people using the wrong model”. It’s people using the wrong prompting mode.
Without a mode choice:
You treat Discovery like Execution: You ask for an “IC pack” before you’ve clarified the investment thesis, risk boundaries, and decision criteria.
The Result: a polished document that is directionally wrong - high credibility veneer, low decision usefulness.You treat Execution like Discovery: You stay in brainstorming indefinitely, generating option overload and never landing a decision-ready artefact.
The Result: time sink, “AI theatre”, and stakeholder impatience.Novices over-delegate: A junior analyst asks for market comps, regulatory interpretation, or lease risk conclusions without guardrails.
The Result: plausible-sounding inaccuracies that slip into deliverables and create reputational or compliance risk.Experts under-specify: A senior person assumes the model “knows what I mean” and provides thin context.
The Result: generic output, hidden assumptions, and brittle analysis.Teams don’t share a prompting language: Everyone prompts differently, so outputs are inconsistent, review is slower, and governance becomes hand-wavy (“Just be careful with AI”).
THE FRAMEWORK EXPLAINED
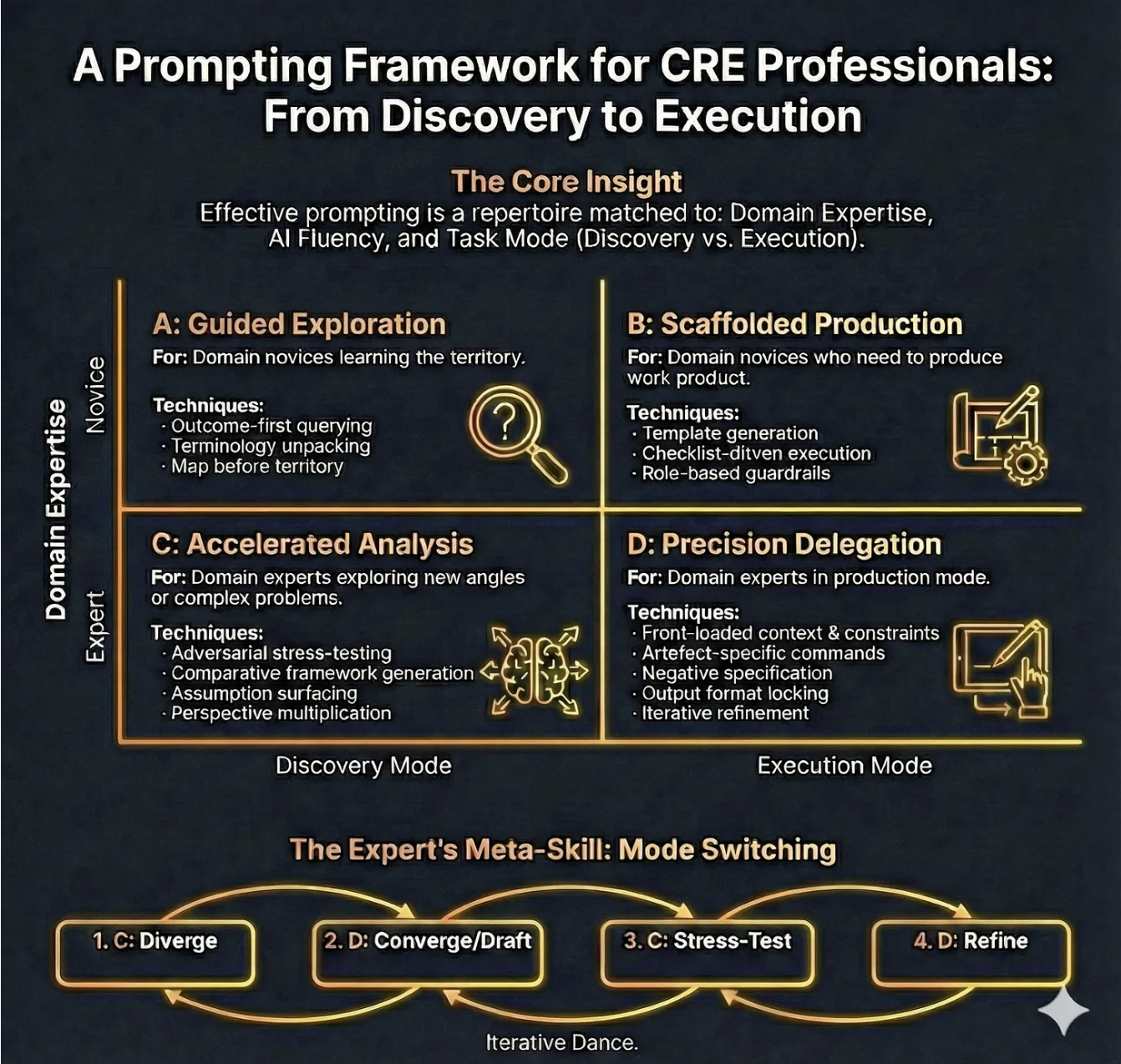
Core Insight (Domain Expertise × AI Fluency × Task Mode)
The intent of the framework is to remind you that “good prompting” is not a universal template. It is a repertoire you select based on who you are in that moment (expert/novice), what you are doing (discover/execute), and how comfortable you are with AI as a collaborator.
How to Use It
Before you type anything substantial, force a 10-second classification:
Am I effectively a novice or expert for this problem?
Am I in Discovery or Execution mode?
What is my AI fluency - do I know how to specify constraints, request assumption registers, and force checkability?
Typical mistakes:
Confusing seniority with domain expertise for the task.
Skipping “task mode” and asking for outputs too early.
Treating AI fluency as irrelevant (“I’m a real estate person, not a prompt engineer”).
CRE example: You are an experienced office investor exploring PBSA for the first time. You are an expert in underwriting discipline but a novice in this asset’s demand drivers and operational risks. You should start in A (Guided Exploration) and quickly move into B (Scaffolded Production) for structured outputs, rather than pretending you are in D.
Quadrant A: Guided Exploration (Discovery mode × Domain novice)
For: Domain novices learning the territory.
Technique 1: Outcome-first querying
Intent: Anchor exploration in the decision you eventually need to make.
How to use it: Ask for the shape of an answer before the content. Start with “What would a good answer look like?” or “What decision does this inform, and what inputs would it require?”
Typical mistakes: Asking for facts and figures before you know which facts matter; accepting an answer that isn’t decision-linked.
CRE example: “I’m evaluating a retail park acquisition. Outline the top 12 questions an IC needs answered and why each matters (cashflow, leasing, capex, ESG/MEES, risk). Then tell me what data I need to answer them.”
Technique 2: Terminology unpacking
Intent: Reduce ambiguity and prevent false confidence.
How to use it: Ask for definitions, distinctions, and “if you hear X, what does it imply?”
Typical mistakes: Using terms loosely (“prime”, “stabilised”, “reversionary”) and letting AI mirror your vagueness.
CRE example: “Explain the difference between ERV, passing rent, and headline rent in a UK multi-let office; list common traps when comparing deals.”
Technique 3: Map-before-territory
Intent: Build a conceptual map before you go deep.
How to use it: Ask for frameworks, taxonomies, checklists, and causal diagrams that organise a domain.
Typical mistakes: Diving into detailed drafting without a map; treating a single framework as “the truth”.
CRE example: “Create a taxonomy of data-centre underwriting risks: power, planning, customer concentration, capex, supply chain, grid constraints, and exit liquidity - then explain how each category shows up in diligence.”
Quadrant B: Scaffolded Production (Execution mode × Domain novice)
For: Domain novices who need to produce work product.
Technique 1: Template generation
Intent: Reduce cognitive load by producing a strong structure that you fill with verified inputs.
How to use it: Request a deliverable skeleton with headings, subheadings, and placeholder prompts for required data.
Typical mistakes: Letting AI fill placeholders with invented content; confusing a template with a conclusion.
CRE example: “Generate an IC pack structure for a UK office acquisition. For each section, include: required inputs, typical analyses, and ‘red flag’ questions. Use placeholders rather than invented numbers.”
Technique 2: Checklist-driven execution
Intent: Shift quality from “hope” to “process control”.
How to use it: Ask the model to create a completion checklist and a review checklist (what to verify; what to cite; what cannot be assumed).
Typical mistakes: Only checking the final narrative, not the underlying assumptions and calculations.
CRE example: “Create a QA checklist for a lease abstract summary used in underwriting: items to verify, clauses that must be escalated, and what constitutes ‘insufficient evidence’.”
Technique 3: Role-based guardrails
Intent: Force the model to behave like a constrained assistant, not a confident commentator.
How to use it: Assign a role plus rules: ask clarifying questions, provide an assumptions register, avoid fabricating, flag uncertainties.
Typical mistakes: Overly theatrical roles (“be a genius investor”) instead of operational constraints; failing to require uncertainty labelling.
CRE example prompt pattern (short):
Act as a CRE analyst. If key inputs are missing, ask for them. Use placeholders rather than guessing.
Provide:
(1) Assumptions register,
(2) Data required list,
(3) Draft output.
Do not invent rents, yields, or regulatory claims.
Quadrant C: Accelerated Analysis (Discovery mode × Domain expert)
For: Domain experts exploring new angles or complex problems.
Technique 1: Adversarial stress-testing
Intent: Use the model as a structured critic to surface fragility.
How to use it: Ask for a red-team review: “If this is wrong, how would it fail?” Force concrete failure pathways.
Typical mistakes: Asking for “pros and cons” (too generic); not tying critique to evidence requirements.
CRE example: “Red-team this investment thesis: ‘Grade A offices will rebound due to flight to quality’. Identify 8 ways it fails, what early signals would show failure, and what mitigations exist.”
Technique 2: Comparative framework generation
Intent: Avoid single-lens thinking by generating multiple analytical frames.
How to use it: Request 3–5 alternative frameworks (e.g., demand-side, regulatory, financing, operational) and compare what each highlights.
Typical mistakes: Treating frameworks as decoration rather than decision tools.
CRE example: “Analyse a workplace strategy decision using three frames: productivity/performance, talent/retention, and cost/risk. Where do they conflict?”
Technique 3: Assumption surfacing
Intent: Make hidden assumptions explicit so they can be tested.
How to use it: Ask the model to list assumptions, classify them (critical vs minor), and propose validation methods.
Typical mistakes: Allowing assumptions to remain embedded in prose.
CRE example: “List all assumptions embedded in a ‘stabilised income’ valuation narrative and propose which can be evidenced vs which require judgement.”
Technique 4: Perspective multiplication
Intent: Create decision robustness by simulating stakeholder lenses.
How to use it: Ask for outputs from specific perspectives: IC chair, lender credit, occupier, planner, ESG committee, asset manager.
Typical mistakes: Using caricatures; failing to produce actionable questions.
CRE example: “From a lender’s credit committee perspective, what are the five deal-breakers in this business plan? What evidence would satisfy each?”
Quadrant D: Precision Delegation (Execution mode × Domain expert)
For: Domain experts in production mode.
Technique 1: Front-loaded context & constraints
Intent: Replace ambiguity with bounded execution.
How to use it: Provide the scenario, the decision context, constraints, definitions, what not to do, and your preferred format.
Typical mistakes: Under-specifying constraints; assuming the model knows your house style; forgetting confidentiality boundaries.
CRE example: “Draft the ‘Risks & Mitigations’ section in our IC style: short bullets, no marketing language, each risk must have an owner and a mitigation plan.”
Technique 2: Artefact-specific commands
Intent: Tell the model exactly what artefact you are producing (memo, IC section, lease clause summary, board slide) and the acceptance criteria.
How to use it: “Produce X, for audience Y, with length Z, and include A/B/C elements.”
Typical mistakes: Asking for “a report” instead of a defined artefact.
CRE example: “Write a 250-word executive summary for an IC: thesis, key numbers placeholders, top 3 risks, recommendation.”
Technique 3: Negative specification
Intent: Prevent known failure behaviours.
How to use it: Explicitly prohibit: invented numbers, uncited claims, legal conclusions, unbounded scope, buzzwords.
Typical mistakes: Only saying what you want, not what you don’t want.
CRE example: “Do not reference specific regulations unless I provide text. If uncertain, flag as ‘needs legal check’.”
Technique 4: Output format locking
Intent: Make outputs reusable and reviewable.
How to use it: Fix headings, bullet structure, and required sections (assumptions; data gaps; confidence).
Typical mistakes: Letting format drift across iterations; mixing analysis and narrative.
CRE example: “Use exactly these headings: Background; Investment case; Key sensitivities; Risks; Mitigations; Open questions.”
Technique 5: Iterative refinement
Intent: Improve quality through controlled revision rather than re-prompting from scratch.
How to use it: Run short cycles: “Revise only section 3; keep the rest unchanged; incorporate these three changes.”
Typical mistakes: Rewriting everything (introduces new errors); failing to track what changed.
CRE example: “Revise the leasing section to reflect a 12-month void assumption and add two mitigations; do not change other sections.”
The Expert’s Meta-Skill: Mode Switching (C → D → C → D)
Intent: Experts get better outcomes by alternating between:
C (Diverge): generate options, risks, questions, frames
D (Converge/Draft): lock format, draft deliverable
C (Stress-test): red team, assumption checks, scenario attacks
D (Refine): tighten, align, finalise, QA
Typical mistake: Staying in one quadrant because it feels productive (either endless ideation or premature drafting).
CRE example: In underwriting, use C to expand risk hypotheses, D to draft the IC narrative, C to stress-test with lender/IC lenses, D to produce the final pack with an assumption register and clear decision asks.
WHY BOTHER
Perhaps this reads as prescriptive. In a way it is. Until it becomes muscle memory. Then you can iterate and ‘free solo’ your way to exceptional outcomes. The discipline is in knowing why you are doing X in Y order,
This is workflow control. You already manage risk with checklists, templates, and IC disciplines. This framework simply extends that discipline to AI-assisted work.
Use it as a structured assistant: to generate your own work frameworks, surface assumptions, draft formats, and run adversarial critique - tasks where reliability comes from constraints and review.
Do make the effort for ‘Mode switching’, because this replaces rework. It’s a slow way to get where you need to fast. Without pushing in then zooming out you miss so much, and so often that means endless versions before a final outcome. This foreshadows that by stress testing as you go.
In Quadrant D, which requires artefact-specific commands and format locking, you can upload your own house style and templates and jump straight to outputs that are ready to go.
And if you are worried that your messy data means none of this will work very well, this is exactly why you need assumption surfacing and evidence plans. The framework makes uncertainty explicit. Once known you can fill in the gaps.
Here’s a 10-minute quick start you can try out today.
Pick one live task you’re doing this week (IC pack, lease summary, board note).
Decide Discovery vs Execution. Decide whether you’re a novice or expert for that task.
Run one prompt from the matching quadrant:
A: ask for a map and definitions
B: ask for a template with placeholders + checklist
C: ask for assumption register + red team
D: lock format + constraints + negative spec
Add one mandatory control: “No invented numbers; use placeholders; list missing inputs.”
Save the best prompt as your team’s starting template.
Working with this framework will lead to compounding returns. Referencing back to the Anthropic study, how we prompt the AI determines how effective it can be.
A closing caution: this framework makes AI collaboration more effective, but “more effective” applied to the wrong task simply accelerates waste. Prompting discipline without task discipline is efficiency theatre with better production values.
This is the third in a stack of frameworks, and sequence matters. RIRA asks the strategic question: how are we creating value—faster taxis, better taxis, or Uber? The CRE Automation Matrix asks the analytical question: what kind of work is this, and what’s the right human-AI interaction model? This Prompting Framework answers the operational question: how do we actually get that work done?
Work the stack top-down. If you haven’t passed the “faster taxis or Uber?” test, no prompting technique will rescue you from building the wrong thing more efficiently. Start with strategy, filter through analysis, then reach for this framework when you’re ready to execute properly.