The PropTech Apocalypse
And why you need RIRA
Summary: Over $300 billion in software market value was erased in a single day. This piece explains why - and what it means for commercial real estate. Using the RIRA framework applied to an investment deal workflow, I show how AI is swapping old constraints for new ones, where value is migrating, and why the firms that own the data layer and the execution layer will capture the next cycle’s profits. It’s a long read. It’s meant to be.
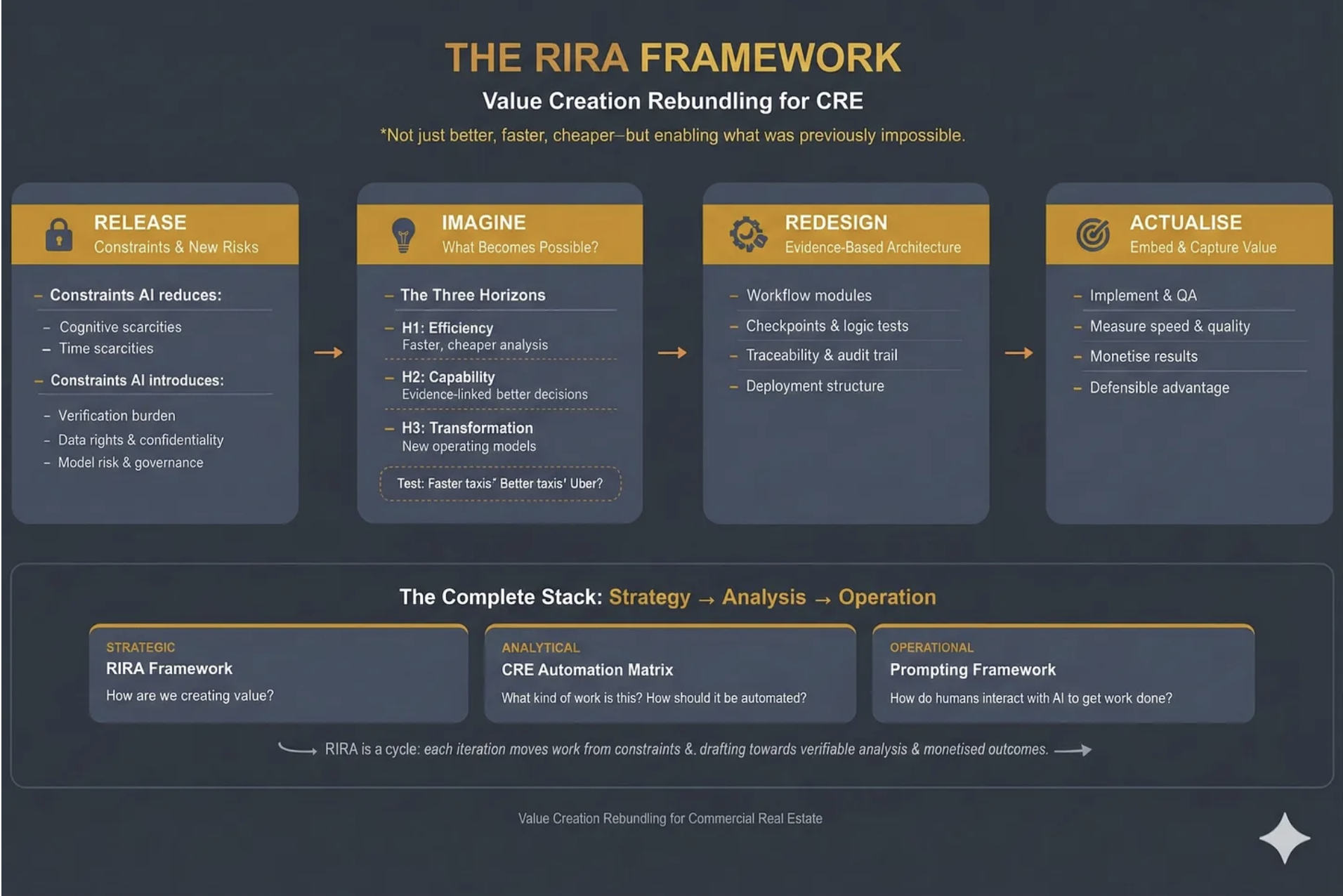
Over the last three weeks I’ve introduced three frameworks - the CRE Automation Matrix, Prompting for CRE Professionals and the RIRA (Release, Imagine, Redesign, Actualise) Framework itself. This week I want to show you RIRA in action, as an example for how it can be incorporated throughout your business.
But first, let’s talk about what happened on Wall Street at the start of February.
$300 Billion Erased
February opened with a software massacre.
On Tuesday the 3rd, according to Forbes, over $300 billion in market value was erased from the software sector in one trading day
“Several of the most entrenched enterprise software companies fell sharply in a single day. Salesforce, ServiceNow, Adobe, and Workday each dropped around 7 percent. Intuit fell nearly 11 percent. At the same time, valuation multiples across the sector compressed violently. The average forward earnings multiple for software companies collapsed from roughly 39x to about 21x in just a few months.”
Wall Street called it the “SaaS-pocalypse.“
This was less a random correction and more a fundamental repricing. The market is waking up to something the venture capital world has been whispering about for months: the software model that dominated enterprise technology for two decades is structurally breaking.
The Thesis: Why Software is Being Hollowed Out
The argument is as follows, and it maps onto commercial real estate with uncomfortable precision.
For twenty years, businesses bought software to help humans organise their work. Dashboards. To-do lists. Complex menus. You paid for a “seat” - a licence for your employee to log into a system. The software didn’t actually do anything. It was a digital filing cabinet. Your employee still had to log in, click buttons, enter data, send emails.
You paid twice. Once for the software. Once for the salary of the person operating it.
The thesis is straightforward: if AI can now execute tasks, paying for software that merely organises human tasks is becoming a bad investment. The industry is converging on this from multiple directions - Phil Fersht at HFS Research calls it “Services-as-Software,” a16z frames it as “software eating labour,” I’ve described it as “Outcomes-as-a-Service.” The labels differ but the signal is the same: not tools that assist the user, but systems that replace the user’s labour. Not dashboards that show you what needs doing, but agents that do it.
This creates what I’ve been calling the “barbell effect.” If the middle layer of software - the screens humans look at to manage tasks - is being hollowed out, value migrates to two poles. At one end: the data layer. AI agents cannot function without accurate, structured, proprietary data. Your lease data, payment history, building performance records - these become more valuable, not less. At the other end: the agent layer. Systems that actually execute work - negotiate a lease, dispatch a vendor, rebalance an HVAC system, screen an acquisition.
The middle - standalone CRMs, basic dashboards, static reporting tools, “thin wrapper” applications that put a digital skin on a manual process - gets crushed.
Clayton Christensen’s ‘conservation of attractive profits’ is the key: when a layer commoditises, profits don’t die - they move to adjacent layers where differentiation still matters.
What looked like “$300 billion erased” is the market repricing where future margins will sit: away from software that organises human work, and towards the layers that own the data and execute outcomes.
The question for every CRE professional is: which side of the barbell are you building on?
The question for every PropTech company is: are we facing our own apocalypse, and what can we do about it?
This is where RIRA comes in. As a strategy-to-execution framework for rebundling value creation in commercial real estate under conditions where AI materially changes the unit economics of analysis and content production, it helps you develop new products and services that leverage, rather than are crushed by, AI.
RIRA in Action: The Investment Deal
To demonstrate the process of using RIRA I am going to use the example of ‘The Investment Deal’. How might the way we deal with deals develop in a heavily AI-mediated world?
RIRA, which stands for ‘Release-Imagine-Redesign-Actualise’, is a way of looking at a workflow through four lenses, where each lens depends on the previous one, and the power comes from following the thread all the way through.
I’ve chosen an investment and capital markets workflow because the constraint-swaps at each stage are the most vivid, the evidence is the most concrete, and the implications are the most strategically significant. At the end, I’ll sketch how the same logic applies everywhere else.
Release: The Analyst Bottleneck Dissolves - and a New One Appears
The Release lens is about what constraints AI removes, and which new constraints it introduces.
Every acquisitions professional knows this workflow intimately. An Offering Memorandum arrives. A junior analyst extracts data from the PDF. Types it into Excel. Massages the assumptions. Builds an ARGUS model. Runs comps. Drafts an Investment Committee memo. Repeat.
A typical CRE acquisition consumes 30–50 analyst hours on data extraction alone. Deal volume is capped by how many OMs a human team can physically process. Firms miss opportunities not because the deals aren’t there, but because they lack the manpower to review them.
AI tools are already releasing this constraint. We are seeing tools (vendor-reported) that generate full five-year cash flow models and IRR analyses in under five minutes with (allegedly) 99%+ extraction accuracy. Others that achieve 95% faster approvals with 400% better risk detection than human reviewers. Firms using these tools report handling 3–4× more deals with the same staff. The precise numbers warrant scrutiny - vendor benchmarks rarely survive contact with messy, real-world portfolios - but the direction of travel is clear.
But, and this is the core insight of the Release stage, AI never just removes a constraint. It swaps it for a new one.
The old bottleneck was throughput: we couldn’t screen enough deals. The new bottleneck is explainability. An Investment Committee cannot approve a £100 million acquisition based on “trust me” from a model. Dealpath, in a recent survey, reports that 93% of institutional firms cite significant AI adoption barriers, with 43% lacking internal expertise. The binding constraint shifts from speed to trust. If the AI cannot show its working - if the outputs aren’t auditable, traceable, and defensible - the speed is worthless.
Data quality becomes an equally hard constraint. If the underlying data is fragmented or dirty, the AI will confidently produce bad returns. “Clean data” becomes the new prerequisite for speed.
Diagnostic question: If we could screen ten times as many opportunities tomorrow, what breaks first - governance, explainability, data quality, decision rights, or IC bandwidth? That’s the new binding constraint, and it’s where execution will stall unless you redesign around it.
Imagine: The 24/7 Deal Hunter
The Imagine lens is about what becomes possible, given the new technologies at your disposal.
If the marginal cost of intelligence drops to near zero, what becomes possible?
Across three horizons: H1 for what becomes more efficient, H2 for what new capabilities can we develop, and H3 for what transformation is now possible?
Think taxis - they could be faster, or maybe they could accept credit cards or… well they could become Uber.
Imagine an investment firm where no human performs data extraction. A sourcing agent continuously monitors thousands of inputs - public listings, court filings for distress, planning/zoning changes, demographic shifts, permit applications. It doesn’t just search. It reasons. It holds the firm’s specific investment thesis - “value-add multifamily in growth markets with strong transport links” - and when it identifies a potential asset, it performs a preliminary underwrite. It ingests the rent roll regardless of format, maps it to the firm’s chart of accounts, pulls real-time tax and insurance comps, and runs a ten-year DCF. The human principal receives a deal memo only for assets that clear the IRR hurdle.
If we could combine market intelligence, debt capacity analysis, and portfolio fit scoring in a single system, and run it autonomously, 24/7/365, we’d have enabled something pretty special. Are we there yet? No, but the likes of JLL (building on the skyline technology they bought a few years ago) and Cherre, building on their years of data wrangling, are getting there.
The critical distinction: this isn’t “a better dashboard.” It’s the elimination of the entire analyst-receives-OM → manual-data-entry → build-ARGUS-model → manual-comp-research → IC-memo workflow. The human enters at the judgement stage, not the extraction stage. The role of the analyst doesn’t disappear - it transforms from “data processor” to “decision validator.”
Design question: If the marginal cost (and time) of analysis and execution tends toward zero, what should we now do that we currently don’t - because it was previously uneconomic or too slow? Where should the system run 24/7, and where should humans enter purely for judgement, not extraction?
Redesign: Dismantling the Excel Industrial Complex
The Redesign lens is about building an evidence-based architecture for new workflows.
The Imagine stage showed us the destination. The Redesign stage is the engineering - how do we physically rebuild our data and workflows to get there?
The core problem has a name that every CRE professional will recognise: the Excel Industrial Complex.
Today, an investment model is a spreadsheet. The moment that file is saved, it is dead. It is a snapshot in time that does not update when interest rates change, a tenant vacates, or the market moves. When you want to test a new scenario, someone manually changes the inputs and saves a new version. Knowledge lives in filenames: “Model_v7_FINAL_FINAL_JB_edits.xlsx.”
The Redesign phase replaces this with what I’d call a Live Financial Twin - an investment model that is a living software object connected to the market.
Underneath that sits the real asset: the canonical deal graph - a structured schema that captures asset terms, counterparties, risks, covenants, and underwriting assumptions as first-class objects, not cells in a spreadsheet. Crucially, it preserves model lineage: every assumption and output is traceable back to source evidence (the specific clause, rent roll line, comp, rate series, or email confirmation) with an auditable chain of custody.
This is where you’d map the workflow against the CRE Automation Matrix — identifying which components are candidates for full automation, which need human-in-the-loop gates, and which remain irreducibly human judgement.
The architecture would have three layers. First, an ingestion layer: OCR and NLP tools ingest documents - rent rolls, tax bills, service charge packs - and convert them into structured data objects, not spreadsheets. Second, live connections: the model is connected via API to real-time market feeds. If the ten-year gilt yield moves, the model automatically updates the cost of debt and recalculates the IRR. You don’t wait for an analyst to notice. Third, write-back capability: when a decision is made - “approve budget,” “proceed to exclusivity” - it doesn’t just sit in meeting minutes. It writes back to the accounting system and updates the forecast automatically.
But notice the new constraint this introduces. If the model is live and automated, you need verification architecture that didn’t previously exist. You need what some are calling “Auditor Agents“ - secondary models whose sole job is cross-checking the maths and logic of the primary underwriting agent. You need human-in-the-loop gates at specific decision points. You need an audit trail that can satisfy both your IC and your regulators.
This is where the barbell becomes concrete. The value accrues to whoever owns the “canonical deal graph“ - the structured, permissioned, auditable data layer - and its agent interfaces. Not to whoever has the prettiest dashboard.
Engineering question: Where are we relying on humans to bridge systems - and what would it take to replace those bridges with a canonical deal graph and auditable model lineage tied to source evidence?
Actualise: From Effort to Edge
The Actualise lens is about embedding and capturing value - turning capability into competitive advantage and revenue.
The first three stages created capability. The Actualise stage answers the question that matters most: how do we capture the value, and how do we stop it leaking to competitors?
Start with what’s changed about what you’re selling. The traditional investment advisory model charges for effort - analyst hours, transaction fees, AUM-based management fees that are proxies for headcount. But if the workflow you’ve redesigned can screen ten times the deals with the same team, the effort-based model actively penalises you for being good at this. You did the work in three minutes; you can’t credibly bill for thirty hours.
The business model has to shift from charging for effort to charging for outcomes: time-to-decision, risk-adjusted conviction, deal throughput, yield improvement. This isn’t a cosmetic change. It requires rethinking fee structures, incentive alignment, and how you demonstrate value to LPs and Investment Committees. But it’s also where the margin expansion lives. The firms that cling to effort-based billing in an AI-accelerated world are subsidising their competitors’ transition.
Next, recognise where the moats actually form. If you’ve built the architecture described in the Redesign stage - the canonical deal graph, live financial models, auditable lineage - you now own something that compounds. Every deal screened enriches the dataset. Every assumption validated sharpens the model. Every IC decision recorded becomes training signal. A competitor starting today doesn’t have your technology and they lack your years of structured deal intelligence. This is the data flywheel, and it is the deepest source of defensibility in the new landscape. It is conservation of attractive profits made concrete: the proprietary data layer becomes the locus of value.
Finally, look for the profit pools you didn’t plan for. Well-architected data infrastructure generates optionality. A firm that built audit-grade, real-time performance data for underwriting purposes discovers it can also price transition risk more accurately than peers, or license anonymised benchmarking data, or offer LPs portfolio-level transparency that compresses their cost of capital. These adjacent opportunities weren’t the original design objective but they are emergent properties of having built the data layer properly. The firms that capture them are the ones that recognised their data infrastructure as a platform, not just a workflow tool.
Business model question: Where are we still charging for effort (hours, seats, process friction) when the value we deliver is actually an outcome (risk reduced, yield improved, time-to-decision shortened)? And which datasets are we generating today - currently treated as operational exhaust - that could become compounding advantage if captured, structured, and reused?
RIRA AS FLYWHEEL
I’ve presented these stages sequentially because that’s how writing works - you read one section after another. But RIRA isn’t a linear process. In practice, you’ll find that the Redesign stage surfaces constraints you didn’t identify in Release. The Actualise stage reveals profit pools that send you back to Imagine with new questions. The framework is iterative by design — each pass through it sharpens your understanding of where value is forming and where it’s migrating. The power isn’t in completing four stages; it’s in the quality of the loops between them.
For instance, when you reach the Redesign stage and discover that your data architecture requires auditor agents and human-in-the-loop gates, that’s a new constraint — which sends you back to Release with a sharper question. And when Actualise reveals that your underwriting data could be licensed as a benchmarking product, that’s a new possibility — which sends you back to Imagine with a business model you hadn’t considered. The framework tightens with each pass.
And because the framework adapts to whatever constraints a given domain surfaces, the same iterative logic applies well beyond investment deals.
The RIRA Pattern Holds Everywhere
I chose the investment deal because the constraint-swaps are vivid, the evidence base is deep, and the stakes are high enough to hold your attention. But the logic isn’t specific to capital markets. It’s structural.
Every CRE workflow has a binding constraint that AI is about to release. Every released constraint produces a new one that nobody was planning for. Every new possibility demands redesigned architecture. And every redesigned architecture creates value that migrates somewhere - the only question is whether it migrates to you or away from you.
Take leasing. The released constraint is responsiveness - business hours, language barriers, the sheer friction of human-to-human scheduling. EliseAI already automates 90% of prospect interactions across 70% of the top 50 US rental operators. That’s a real number, today. But follow the thread. The new constraint isn’t technological, it’s regulatory. When algorithms optimise pricing and availability across an entire portfolio, you’ve crossed from operational efficiency into territory that regulators recognise as market coordination. The US Department of Justice’s lawsuit against RealPage is the canary. The firms that saw leasing automation purely as a cost play, without redesigning their compliance and governance architecture, are now exposed to a constraint they never anticipated. Release → new constraint → architectural consequence. The pattern holds.
You can run this logic through facilities management, asset management, development, valuation, property management - any workflow where humans currently bridge between systems, interpret data, or make routine decisions under time pressure. The binding constraints differ. The new constraints that emerge will differ. The architectural responses will differ. But the sequence is invariant, and that’s what makes RIRA a framework rather than just a case study.
If you’re wondering how RIRA applies to your specific workflow - leasing operations, portfolio strategy, facilities management, tenant experience - that’s precisely what we work through, step by step, in my forthcoming course. The investment deal example gives you the logic. Applying it to your own context is where the value compounds. It’s also where the non-obvious constraints - the ones that only surface when Release, Imagine, Redesign and Actualise interact - tend to catch firms out. Contact me for details.
The Takeaway
The $300 billion that was erased from software stocks is a signal, not an anomaly. Value is moving. It’s moving from tools that organise human work to systems that execute it. From dashboards to data layers. From seats to outcomes.
Christensen was right: when one layer commoditises, attractive profits don’t die - they change address.
And in this cycle, they’re migrating towards data ownership and execution.
The RIRA framework is a way of thinking clearly about where it’s moving in your specific context - and making sure you’re building on the right side of the barbell when it arrives.
And a way for PropTechs to avoid their own apocalypse. Or at least see it coming.