
THE BLOG
AI: Widespread Adoption. Shallow Usage.
The 3rd Annual AI in Real Estate Survey reveals an industry that has access to AI - but not seriousness about AI.
In 2024, curiosity. In 2025, experimentation. In 2026? A gap. Between access and depth, between awareness and action, between what the industry says it believes and what it’s actually doing about it.
You can download the full report here.
The Headline
93% of respondents now have access to AI tools at work. That number is essentially settled.
But only 7% describe their organisation as fully integrated.
Two-thirds haven’t moved past basic chat. A third describe usage as entirely ad hoc - individuals doing their own thing, with no organisational strategy behind it.
The industry has the tools. What it doesn’t have is seriousness about the tools.
Everyone Has a Hammer. Almost Nobody Has a Blueprint.
The survey paints a picture of a sector that has passed the access test and is now failing the maturity test. The numbers tell the story clearly:
34% of organisations use AI on a purely ad hoc, individual-driven basis. Another 23%are still trialling. Only 34% have implemented AI in defined business areas, and a mere 7% are fully integrated.
Microsoft Copilot leads daily usage (49%), largely because it’s the only tool many organisations sanction. ChatGPT follows (37%), but with a big caveat: much of that usage is shadow AI - individuals using personal accounts because they find the approved tools less capable. One respondent put it bluntly: their company provides Copilot, but for non-sensitive work they find Gemini, Claude and ChatGPT give better answers.
This is significant. Corporate AI strategy in most CRE firms is being driven by procurement and IT security, not by capability or user experience. People are voting with their feet. And the gap between what organisations sanction and what individuals actually use creates compliance, confidentiality and consistency risks that most firms aren’t equipped to manage.
Two-Thirds of the Industry Is Still Using AI Like a Search Engine
When the survey asked which advanced capabilities people actually use, 69% said standard chat and transcription. That’s it. The foundational level.
Knowledge management? 43%. Custom instructions? 36%. Deep research? 36%. Procedural training and skills? 31%. Live collaboration tools? Just 16%.
The gap between using a chatbot for ad hoc queries and embedding AI into repeatable, governed workflows is the gap between having AI and using AI. Most of the industry is on the wrong side of that line.
The dominant use cases confirm this: transcription, summarisation, drafting. The boring stuff. And 87% of respondents say the boring stuff is exactly what they want AI to handle. Which is fine - except that the boring stuff is increasingly table stakes. Transcription and summarisation are being baked into standard software. They’re hygiene factors, not differentiators.
The firms pulling ahead are doing something different: building knowledge systems, creating structured prompting frameworks, developing custom workflows, deploying AI agents. One respondent described having six operational AI agents in business workflows with twelve more in the build phase. They’re an outlier - but it’s the direction of travel.
The Trust Gradient
The survey reveals a trust hierarchy. Respondents trust AI most for summarisation (75%), meeting transcription (66%), and content drafting (59%). Trust drops as stakes rise: negotiation strategy (30%), property valuation (16%). Eleven per cent don’t trust AI with any of the listed tasks.
This is troubling. While care needs to be taken with these tools, blanket dismissal is indicative of veneer-like understanding. Used well they are enormously powerful right up the intellectual value tree. ChatGPT 5.4 outperformed, or tied, with humans across 83% of ‘knowledge work’ tasks within the ‘eval’ GDPVal. The industry is stuck in a mindset that they are only for trivial work.
The Number That Should Keep You Up at Night
58% of respondents believe the time-based fee model is the most vulnerable part of CRE’s business model.
Read that again.
These are, in many cases, the same professionals who earn time-based fees. They are telling you - in a survey, anonymously, with no incentive to exaggerate - that the way they charge for their work is the element most at risk from AI.
AI collapses the time required for many tasks. What used to take a junior analyst three days now takes an afternoon. What used to take a partner two hours of document review takes ten minutes. The input - time - is compressing. And when clients notice (they will), they will reset expectations about what an hour of advisory time is worth.
The second most vulnerable element? The Information Edge (18%) - the proprietary market data that research-led firms have historically treated as a competitive moat. As AI gets better at synthesising public data, that moat is being drained.
Only 6% believe relationships will fully protect fee structures. They may be right in the short term. But it’s a position that gets harder to defend every quarter.
The Governance Deficit
30% of organisations have a comprehensive AI governance policy. 21% have something basic. But 16% have no policy and no plans to create one. Another 10% don’t even know whether a policy exists.
That means roughly a quarter of the industry is operating AI tools - handling sensitive commercial and financial data - with no governance framework and no apparent urgency to build one.
You can’t govern what people don’t understand. And you can’t build governance for tools that people are using in the shadows.
The shadow AI problem and the governance deficit are two sides of the same coin. Employees use personal AI accounts because the approved tools feel restrictive. Organisations lack governance because they haven’t invested in understanding what their people are actually doing with AI. Both problems trace back to the same root cause: insufficient training and strategic intent.
Training Is the Anchor on Everything
Cultural resistance and understanding gaps are the most viscerally felt barrier to adoption. As one respondent put it: people know AI is important or powerful, but a lot do not know practically what this means.
You can’t redesign workflows if people don’t understand what the tools can do. You can’t build governance if the people writing the policies have never spent serious time with the technology. You can’t adopt agentic AI if your team thinks ChatGPT is just a search engine with better manners.
Training isn’t a nice-to-have. It’s the prerequisite for everything else - governance, workflow redesign, cultural change, business model adaptation. Without it, firms are stuck in a loop: shallow adoption generating shallow results, reinforcing the perception that AI isn’t that transformative, justifying further underinvestment.
Jobs: Not Elimination, but Redesign (and fewer of them)
Despite the low serious adoption and rather dismissive attitude towards AI (especially in the belief it is for the dreary work) it is striking that respondents expected each of the nine CRE disciplines surveyed to suffer a decline in jobs.
Research (63% expect decrease) and property management (61%) are seen as most exposed. FM the least - but even here over 40% expected a decrease in jobs.
I did think it would be interesting to see the results if everyone knew what the SOTA models were capable of.
But the qualitative responses were interesting. Several respondents emphasised that it’s less about headcount reduction and more about role transformation - fewer administrative tasks, fewer junior information-compiling duties, greater emphasis on judgement, stakeholder engagement and oversight.
One respondent offered a framing reflected across many industries: lower-rank roles like coordinators and analyst support get compressed, but demand for reviewers, approvers and humans-in-the-loop remains strong.
But… the assumption that senior or specialist roles are insulated is, I think, misplaced. As AI becomes more capable of analysis, drafting and knowledge retrieval, all roles shift. The exposure isn’t to the role - it’s to the person who doesn’t adapt their workflow.
Space: Reconfiguration, Not Collapse
On the question of AI’s impact on physical space, the majority view (55%) is reconfiguration: same amount of space, different use. 27% expect contraction. 13% see negligible impact this cycle. Only 5% expect expansion.
This aligns with the thesis I’ve been developing in recent newsletters. The question isn’t simply “will AI reduce headcount and therefore reduce space demand?” The answer depends on a cascade of strategic choices about how firms deploy productivity gains. The same efficiency assumptions can lead to radically different space outcomes depending on whether firms shrink, reinvest, or restructure.
The reconfiguration thesis - a shift from desks to collaboration and experience environments - suggests AI is seen as an accelerant of existing post-pandemic patterns rather than a wholly new force. That’s probably right for the next two to three years, but beyond that we’ll see far more direct impact on demand.
The Divergence
Here’s what I take away from three years of this survey.
The industry has moved from curiosity to experimentation to widespread but shallow usage. Adoption is high; maturity is not. And the gap between the firms that are serious about AI and the firms that merely have access to it is widening.
One respondent captured the stakes perfectly: We are overestimating the impact of AI for the next three years - but it will have a devastating impact on those organisations that haven’t worked out how to get, store and use their IP in five years. It will be like bankruptcy - you go bankrupt slowly and then fast.
The technology is accelerating exponentially. The industry is moving linearly. That mismatch has consequences.
A few firms are building AI agents, custom knowledge systems, and structured prompting frameworks. They are pulling away from the pack.
The rest? Widespread adoption, shallow usage. Lots of tools, not enough thinking.
Time to get serious.
AI & Real Estate: Beyond Generative
The direction is obvious. The speed is what breaks you.
The latest module for #GenerativeAIforRealEstatePeople runs to 9,000 words. This is the core argument, compressed. Course participants get the full version with the scenario frameworks, asset-class analysis, operational horizons, and the uncomfortable questions at the end.
The thesis in one sentence
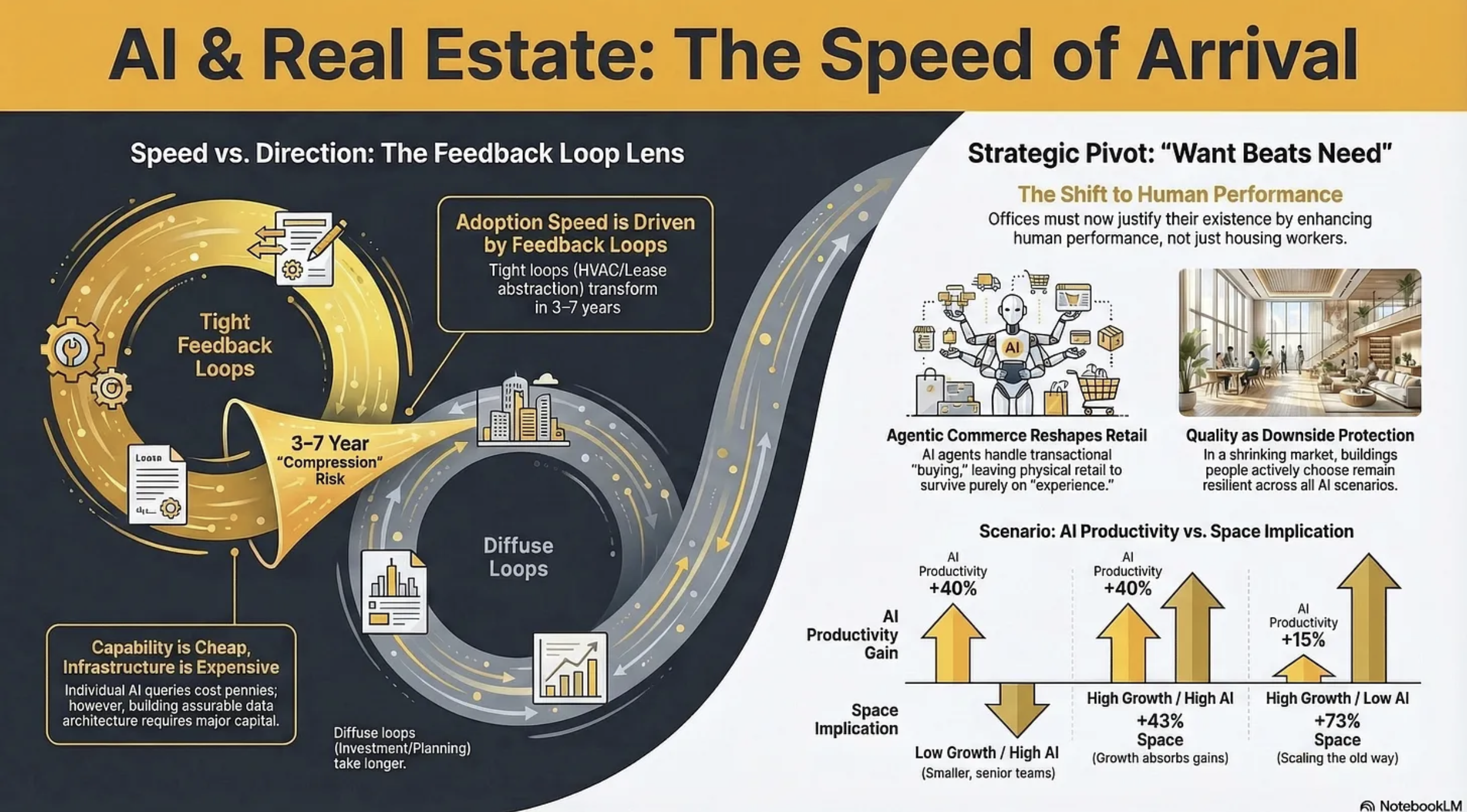
The direction of AI in real estate is largely knowable and mostly uncontroversial. The variable that determines whether your assets appreciate or depreciate is speed of arrival - and the industry has no framework for assessing it.
Why speed, not direction
In 2023, esteemed AI researcher Andrej Karpathy published a diagram showing an LLM as the kernel of a new operating system. Most people read it as a five-year forecast. It arrived in roughly eighteen months.
If the market has 10–15 years to adjust to AI-driven change, outcomes are manageable: portfolios rotate, buildings retrofit, organisations retrain, capital markets reprice gradually.
Compress the same changes into 3–7 years and you get stranded assets, workforce dislocation, and the kind of repricing that destroys value for anyone who moved too slowly.
The course module introduces a predictive lens for this: feedback loops. Domains with tight feedback loops - where you can quickly and objectively measure whether the AI’s output is correct - transform fast. HVAC optimisation, lease abstraction, code generation: these are already being reshaped. Domains with diffuse feedback loops - investment judgement, tenant relationship management, urban planning - change more slowly and less predictably.
For CRE professionals, this creates a split reality. The operational and transactional layers sit in the tight-feedback category. The strategic and relational layers sit in the diffuse category. But the operational transformation inevitably changes the context in which strategic decisions are made. You cannot hold the two apart for long.
What has changed since the first version of this module?
Three of the four original barriers to AI adoption have shifted:
The cost barrier has flipped. Individual AI inference is now negligible. But deploying AI at enterprise scale - the data architecture, integration middleware, cybersecurity, governance - is a serious capital commitment. The firms that understood this early allocated 20% of their AI budgets to technology and 80% to change management. Most did the opposite. Some are still debating whether to start.
Data quality matters differently. Frontier models handle messy, unstructured data remarkably well. The constraint has shifted from “our data isn’t clean enough for AI“ to “our data isn’t structured enough for assurable AI.“ AI can work with your data. The question is whether the outputs are auditable enough for board-level decisions and transaction sign-offs.
Agentic AI changes the integration calculus. The industry’s systemic fragmentation remains real. But AI agents that autonomously navigate between software platforms, APIs, and data sources mean the integration problem is becoming solvable without requiring the entire ecosystem to adopt common standards. This changes the cost-benefit calculation for early movers - which is exactly the dynamic that creates competitive advantage.
What has not changed: deep institutional inertia, fragmented ownership, long asset cycles, misaligned incentives. The destination is locked in; the uncertainty is pace.
Two forces, one asset
The module’s central analytical framework distinguishes two ways AI affects commercial real estate - and then immediately insists you cannot treat them separately.
AI acting ON real estate: new demand patterns, new asset classes, structural shifts in what gets built and where. A capital allocation question. Speed is outside your control.
AI used BY real estate: how existing assets are operated, transacted, valued, and experienced. An operational alpha question. Speed is a competitive variable.
The critical insight is that these are not separate categories to sort assets into. They are competing pressures acting on the same building simultaneously. A prime office is shaped by AI acting on it (changing occupier headcount, raising specification expectations) and by AI used within it (smart building systems, personalised tenant experience, automated FM). The investment outcome depends on whether the owner is deploying AI fast enough to offset the structural pressures AI is creating.
Need declines. Want is what remains.
The deepest argument in the module - the one that sits beneath every section - is a shift in the nature of real estate demand itself.
If AI absorbs the routine knowledge work that currently fills offices, the purpose of the office shifts toward collaboration, mentoring, culture-building, creative work. The same logic applies to retail (experiential over transactional), healthcare (patient-facing over administrative), and any asset class where the human element is the value proposition.
The fundamental question shifts from need to want. And that changes everything about underwriting.
Need-driven demand is predictable, stable, and relatively insensitive to quality. Choice-driven demand is volatile, quality-sensitive, and ruthlessly comparative. An office is no longer competing only against other offices. It is competing against the increasingly viable alternative of not having a central office at all. When the benchmark shifts from “the next best office” to “not having an office,” the bar for what constitutes a compelling offer rises dramatically.
This is uncomfortable for owners of average stock. But it contains a genuine opportunity: you can still win big in a shrinking market if you are building something people actively desire. The polarisation between best-in-class and everything else widens. Quality becomes not just a return enhancer but downside protection protection.
The asset-class implications (in brief)
The full module works through offices, data centres, logistics, healthcare, retail, and four residential sub-sectors. A few highlights:
Offices get a four-scenario framework crossing output growth with AI productivity. The same AI capability can mean 22% less space or 43% more, depending on whether the occupier is growing. No macro model tells you which scenario you’re in. Only your occupier’s specific context does.
Retail confronts agentic commerce - not just e-commerce, but AI agents that research, compare, and purchase on your behalf. This is more destructive to average retail than e-commerce was, because it removes the last functional justification for visiting a mediocre destination. But it simultaneously purifies the demand signal: everyone who walks through the door is there because they want to be.
Logistics gets an agentic commerce multiplier: even if consumer spending stays flat, the volume of goods flowing through fulfilment channels likely increases because agents eliminate the friction that currently constrains transaction volume. The module is honest about the returns question - net effect on return volumes is genuinely uncertain - but the specification requirements for logistics facilities are rising regardless.
Later living has arguably the most compelling operational AI case of any residential segment, because the applications are care-critical, not merely commercial. Health monitoring, predictive intervention, fall detection, loneliness mitigation. AI does not just improve efficiency; it changes the care proposition.
The geography argument
AI may be doing something more subtle than the pandemic’s failed decentralisation prediction. The pandemic proved remote work was technically possible. AI is making it technically excellent. The justification for being in a specific place shifts from “I need to be here to do my job“ to “I choose to be here because the environment is worth the commute.“
The e-commerce parallel is instructive. Online retail didn’t uniformly undermine physical retail. It reshaped its geography - devastating locations that competed on convenience while boosting locations that competed on experience. AI may do the same to office geography: devastating locations that competed on proximity to work while boosting locations that compete on quality of place.
The operational horizon
The module includes a compressed reference map of twelve capabilities across three time horizons (now–2yr, 2–5yr, 5–10yr), classified by feedback-loop type. The tight-feedback, near-term capabilities - HVAC optimisation with sub-one-year payback, AI lease extraction, occupancy intelligence, agentic FM triage - are proven, measurable, and deployable now.
And this produces the module’s sharpest irony: the industry spends most of its analytical energy debating the things it cannot control (will AI reduce office demand by 10% or 20%?) and has not yet deployed the things
it can. The storm is uncertain. The ship-building is not.
What replaces confident forward projection?
The module argues that the pretence of confident 3–5 year NOI projection is becoming actively misleading when the variance of plausible outcomes has widened this dramatically. What replaces it:
Scenario discipline over point forecasts. Not new, but the variables that matter have changed. AI productivity and occupier growth posture are not factors that appeared in traditional CRE stress-testing.
Optionality over commitment. When the range of outcomes is wide, assets and structures that preserve flexibility are worth a premium. The traditional preference for long leases and stable income is a bet on low variance. If AI delivers high variance, that bet loses.
Occupier intelligence over market-level data. The edge moves to granular understanding of individual tenants - their growth trajectory, their AI posture, their industry dynamics.
Quality as insurance. Buildings people choose to occupy are resilient across more scenarios than buildings people are forced to occupy.
Supply constraints and market inertia are not a strategy. They are a sedative.
Where’s the New Business?

A framework for finding where AI creates genuinely new ventures - not just better processes
Over the past three months we’ve built a collection of frameworks for addressing how to leverage AI in CRE: RIRA for strategy, the CRE Automation Matrix for analysis, and the Prompting Framework for execution. Together they answer: how are we creating value, what kind of work is this, and how do we get it done?
But there’s a question they don’t force you to confront.
When participants work through RIRA’s ‘Imagine’ phase - with its three horizons of Efficiency (H1), Capability (H2), and Transformation (H3) - they almost universally gravitate towards H1 and H2. Faster lease abstracts. Better evidence-linked analysis. Smarter compliance checks. All valuable. All necessary.
But none of them are new businesses.
H1 makes your current work faster. H2 makes it better. But H3 builds something that doesn’t exist yet.
And almost nobody gets to H3, not because they lack ambition, but because H1 and H2 are natural extensions of work you already understand. You can picture your workflows done more efficiently. You can picture them done with better evidence. But picturing a product or service that serves a customer who doesn’t yet know they need it, that earns revenue from a budget line that doesn’t currently exist - that requires a fundamentally different kind of thinking. It’s uncomfortable. It implicates your own business model.
Which is exactly why you need a provocation tool to get there.
The H3 Provocation Framework
The H3 Provocation Framework is a set of five questions designed to surface where AI creates genuinely new businesses, products, or market structures in commercial real estate. It sits within RIRA’s Imagine phase as a dedicated instrument for Horizon 3 thinking. It doesn’t replace the “Faster taxis / Better taxis / Uber?” diagnostic, rather it provides the provocations that generate H3 hypotheses in the first place.
WHAT H3s LOOK LIKE IN CRE
Before I describe the five provocations, let me show you what they can produce. I’ve run the framework against four of the most common products and services in commercial real estate - diligence, advisory, occupancy, and portfolio management - to illustrate the kinds of hypotheses that emerge. These aren’t predictions. They’re outputs of a generative process, and the same process can be pointed at any activity across the CRE landscape.
Continuous Diligence.
Due diligence exists as an industry because maintaining a verified, current information state across hundreds of documents requires sustained human attention over weeks. That’s a cognitive and temporal constraint. If AI removes it - keeping an asset’s entire information state continuously current and verified - the question “shall we commission a diligence report?” stops making sense. You don’t commission what already exists. The value migrates from “who can do diligence well” (a cottage industry of lawyers, surveyors, and consultants charging £50–100k per transaction) to “who maintains the verified state.” That’s a data infrastructure play, not a professional services play. Transaction speed becomes a product. The seller offering a continuously-diligenced asset with verified evidence chains commands a premium because they’ve collapsed the buyer’s time and risk.
Evidence-Based Advisory.
AI is about to flood the market with plausible-sounding investment analysis. The supply of professional-looking memos will explode. What won’t explode is the supply of trustworthy analysis - recommendations backed by evidence chains, auditable reasoning, and explicit assumption registers. The value migrates from “trust me, I’m experienced” to “trust the evidence chain, and I’ll interpret what it means.” The human adviser’s role shifts from analyst-packager to interpreter of verified outputs and owner of the final judgement call - pure Quadrant D work (see The CRE Automation Matrix Framework for details). The advisory firm that builds verifiable decision support first doesn’t just have a better product - they’ve made every competitor’s narrative-based approach look unaccountable by comparison.
Occupier-as-a-Service.
What if occupiers didn’t buy space but bought outcomes - guaranteed workspace performance delivered against SLAs rather than lease terms? Air quality, temperature responsiveness, service levels - all continuously monitored, verified, and priced on delivery. The purist version breaks the institutional capital stack (lenders can’t underwrite an SLA the way they underwrite a 15-year FRI lease). But the realistic transition is a hybrid: a conventional lease providing the contracted income floor, with a verified performance premium on top. The hotel sector already proved this model - variable income becomes investable once you have enough verified performance data to make it predictable. PBSA and BTR are moving the same way. Over time, as the data layer matures and investors learn to underwrite operational capability rather than just tenant covenant, the proportions shift. Value migrates from “location plus specification” to “verified performance delivery.”
Portfolio Intelligence as Product.
Large portfolio owners sit on enormous operational data - tenant behaviour, maintenance patterns, energy consumption, lease events - used solely for internal management. If the intelligence derived from that data became a product - benchmarking services, predictive models, optimisation algorithms - you’ve created a revenue stream that doesn’t currently exist in CRE’s business model. The moat is proprietary data combined with verification infrastructure that’s hard to replicate. The REIT doesn’t just earn rental income - it earns knowledge income. And unlike rental income, knowledge products compound: the more data you accumulate, the better the models become, the more customers they attract.
The Common Pattern
Notice what these four share. None of them improve an existing workflow. They each create something that didn’t previously exist as a product or service. They each involve a value migration - a shift in where the premium concentrates. And they each emerged from asking a specific, slightly uncomfortable question about the current state of things.
I chose diligence, advisory, occupancy, and portfolio management because they’re familiar to almost everyone in the industry. But the framework isn’t limited to these. Point it at development appraisal, debt origination, tenant representation, facilities management, fund reporting - any activity where AI is about to change the underlying economics - and it will surface H3 candidates specific to that domain. The five provocations are a lens, not a list.
One more thing worth saying plainly: the timelines on these are uncertain. Continuous diligence may be five years away from mainstream adoption, or three, or seven. The point of the framework isn’t to predict when. It’s to discern the direction of travel - to see where value is migrating so you can start positioning now rather than reacting later. The firms that recognised flexible workspace was a structural shift, not a fad, had years of advantage over those that waited for proof. The same dynamic applies here, across a far wider set of CRE activities.
Those questions are the framework.
THE FIVE PROVOCATIONS
The five provocations follow a narrative arc:
What becomes free →
What falls apart →
What gets built →
Who wins →
Who pays.
Each builds on the last, and the sequence matters.
1. Constraint Collapse - “What becomes free - and whose business breaks?”
Every workflow has a binding constraint - not always cost. Sometimes it’s time, cognitive bandwidth, scale, or access. AI is about to remove some of these entirely. The question isn’t “what gets cheaper?” It’s “whose revenue depends on this constraint existing?” If the answer includes your firm, this is where you need to be paying attention. The continuous diligence hypothesis emerged directly from this question: the constraint wasn’t that diligence was expensive, it was that maintaining a continuously verified information state was operationally impossible regardless of how much you spent. Remove that constraint and the entire episodic diligence model becomes a solution to a problem that no longer exists.
2. The Unbundling - “What are you actually selling - and which part is about to become worthless?”
Every service you charge for is a bundle of components, and you’ve probably never itemised them because the bundle is just “what we do.” AI will replicate some of those components to a verifiable standard. The ones it can’t replicate are where your future premium concentrates. The evidence-based advisory hypothesis came from this: an investment advisory mandate bundles market knowledge, analytical packaging, relationship access, and strategic judgement into a single percentage fee. AI commoditises the first two. The question is whether clients keep paying the same fee for the last two - or start buying judgement separately, possibly from someone who was never an “advisor” before but who now owns the best evidence infrastructure.
3. The New Entrant - “If someone started from scratch today, would they build what you’ve got?”
A well-funded team with no legacy systems, no existing relationships, but full access to frontier AI enters your market. They don’t need to respect how things currently work. What do they build? Who do they sell to? And the question that should keep you up at night: why can’t you build it first? Usually the honest answer is “because our current business gets in the way” - and that’s exactly the answer that should worry you most. The occupier-as-a-service hypothesis is a new entrant question: if you were starting a property management business today, would you build what property management currently looks like? Or would you build an AI-orchestrated operating platform with continuous monitoring, predictive maintenance, and verified performance delivery - that happens to manage buildings?
4. The Control Point - “After this shift, whose signature still matters?”
Value in CRE concentrates around accountability - whoever signs the recommendation, the valuation, the approval. Their signature carries weight because they’re standing behind judgements that can’t easily be verified any other way. When AI changes what can be verified and evidenced, that signature may carry less weight - or shift to someone else entirely. Whoever holds the accountability after the migration holds the value. Consider: a Red Book valuation requires a RICS-qualified surveyor’s signature because comparable selection, adjustment logic, and market judgement need a professional to stand behind them. If AI produces the analysis with full evidence chains, auditable reasoning, and verified comparables, the surveyor’s role shifts from “produce the valuation” to “validate the machine’s output.” That’s a different job, with different economics - and it may not need the same provider.
5. The Customer - “Who has this problem right now - and what are they currently paying to solve it badly?”
The most transformative new businesses don’t create demand from nothing. They serve demand that’s already there but currently met by expensive, slow, or inadequate solutions. The test isn’t “would someone hypothetically pay for this?” It’s “who’s already spending money or losing money because this doesn’t exist yet?” Every institutional buyer who has ever lost a competitive bid because their diligence took two weeks longer than the other side’s is paying the cost of the continuous diligence gap - they’re just paying it in lost deals rather than invoices. Every tenant who signed a lease based on a glossy brochure and discovered the building doesn’t perform is paying the cost of the missing performance verification layer. The customer already exists. They just don’t know yet that what you’re building is the solution.
HOW TO USE THIS
Work through the five provocations in sequence after a standard RIRA pass has produced its H1 and H2 outputs for a specific workflow. Those outputs become the foundation - you’re pushing further, not replacing them. Give each question time to breathe. The uncomfortable answers - the ones that implicate your own firm’s business model - are the ones worth pursuing.
Then classify what emerges. Using AI to produce lease abstracts faster is an H1. Building a lease abstraction system with evidence chains as a firm standard is an H2. Creating a continuously verified portfolio information state that becomes a product you sell to buyers, lenders, and insurers - that’s an H3. The distinction matters because H2s improve your current business while H3s build a new one. Both are valuable. Confusing them leads to underinvestment in the H3 and over-claiming on the H2.
Most ideas will turn out to be H2s. That’s fine. That’s expected. The framework has teeth precisely because it filters honestly. But the one or two ideas that survive all five provocations and still look like genuine H3s - those are worth serious investment of time and thought.
THE COMPLETE STACK
This completes RIRA. The framework has always had three horizons in its Imagine phase, but until now H3 has been a diagnostic label - something you aspire to - rather than a generative method. The five provocations give it teeth. They turn “are we building Uber or a faster taxi?” from a question you ask at the end into a structured process you work through to find out.
The stack remains three frameworks, each answering a different question. RIRA asks how we’re creating value - and now has the tools to push that question all the way to transformation, not just efficiency and capability. The Automation Matrix asks what kind of work this is and how it should be automated. The Prompting Framework asks how we actually get work done. Strategy, analysis, execution.
If your AI strategy starts and ends with doing current work faster, you’re playing an H1 game that everybody else will also be playing within two years. The firms that engineered verifiability into their cognitive work will be pulling ahead. And the firms that ran these provocations honestly, saw the value migration early, and started building - they’ll be playing a different game entirely.
The provocations don’t tell you which game to play. They help you see the games that are available.
Run the five provocations on your most profitable workflow - and note which answer makes you uncomfortable.
AI and Office Space Demand

How much space will you need in 3, 5, 10 years?
A new genre of research is emerging. Call it AI-impact modelling.
The approach goes something like this. Take every occupation in the economy. Decompose each into its constituent tasks - data entry, document drafting, scheduling, analysis, negotiation, physical labour. Score each task for AI susceptibility on a scale of 0 to 1. Weight the scores by how much time each occupation spends on each task. Apply an adoption discount to reflect real-world barriers. Out comes a number: the “practical AI impact” for every job in the economy.
The methodology traces back to Eloundou et al.’s influential 2023/24 paper “GPTs are GPTs,” which assessed GPT-4’s capability against occupational tasks. Since then, the ILO, the OECD, Felten et al., and most recently the UCL/Cardiff GAISI study have all built on or extended the framework. It has become the default approach for estimating AI’s labour market impact.
And the numbers are eye-catching. Depending on whose model you look at, somewhere between 25% and 45% of the average knowledge worker’s tasks are susceptible to AI automation. Apply discount factors for adoption barriers, layer on displacement assumptions and timeline projections, and you get headline figures about millions of FTE capacity freed, hundreds of thousands of office jobs at risk, and tens of millions of square feet of space demand evaporating.
These models are proliferating because there’s a commercial appetite for them. Occupiers want to know how much space they’ll need. Investors want to know whether their assets are exposed. Consultants want to sell certainty into an uncertain market. And a multi-hundred-occupation spreadsheet with scenario matrices and regional breakdowns certainly looks like certainty.
It isn’t.
WHAT THE EVIDENCE ACTUALLY SHOWS
Before I explain why the models don’t work, let me acknowledge that something real is happening. The GAISI study (UCL, Cardiff, Oxford, Surrey - August 2025) found that job postings in AI-exposed occupations were 5.5% lower in Q2 2025 than pre-ChatGPT trends would predict - roughly 84,000 fewer postings per month. The pay premium for AI-exposed tasks fell ~12% between 2017 and 2024. Displacement effects appear, at present, to outweigh productivity-driven gains in labour demand.
But notice what this actually measures: hiring decisions. Firms choosing not to fill roles, restructuring teams, rethinking workflows. The real signal is in the aggregate behaviour of employers, not in theoretical task scores.
WHY TASK BASED MODELS DON’T WORK
Here’s the fundamental problem.
The capability scores are already stale. Every major task-exposure framework was built to assess capabilities circa 2023 - primarily GPT-4. Even GAISI, published in 2025, used GPT-4o and Gemini 2.5 Pro for its task ratings. GPT-4o was not a reasoning model, and while Gemini 2.5 Pro is more capable, both have already been superseded. Current frontier systems are qualitatively different, and in 18 months they’ll be different again. Using a 2023 capability snapshot to project 2031 or 2036 labour markets is like using a 2015 smartphone to predict what your phone would do today.
The adoption discount is a guess wearing a lab coat. These models typically apply a uniform discount - say 0.6 - to all occupations, reflecting the gap between what AI cando and what organisations will deploy. But adoption varies enormously. A fintech processing team will hit 85% AI integration years before an NHS trust reaches 30%. A flat discount applied uniformly creates false precision while masking the variation that actually matters.
The precision is theatrical. When a model tells you that a particular occupation faces a practical impact of 34.332% and will have 12.70284 hours freed per week - that level of specificity implies extraordinary confidence. The real uncertainty band is ±15 percentage points at best. Six decimal places on a qualitative assumption is not data science. It is aesthetics.
And jobs don’t work like this. This is the deepest problem. The entire framework treats occupations as fixed containers with automatable components. You take today’s task mix, score each piece, and calculate what percentage gets “freed up.” But that’s not how AI changes work. What happens in practice is that roles get redesigned, merged, split, and reinvented. A financial analyst who used to spend 40% of their time gathering data doesn’t just get that 40% back as spare capacity. The role transforms. Expectations rise. New responsibilities appear that didn’t previously exist.
The model is treating the subject as a photograph when it is actually a video.
Changing all the time.
In practice, you might as well just guess. You’d get a different number, but it wouldn’t be meaningfully less accurate. And the spreadsheet version is arguably worse than an honest guess - because the aesthetic of precision triggers all manner of anchoring biases in anyone not deeply sophisticated in their data analysis. Hand a board a number with six decimal places and they’ll treat it as a fact. That’s not a useful tool. It’s a crutch that could lead to a string of bad decisions.
THE QUESTION THESE MODELS GET WRONG
But there’s a deeper problem than imprecision, and it comes from recent work by MIT’s David Autor and Neil Thompson.
Their June 2025 paper “Expertise” argues that the standard task-based approach asks the wrong question entirely. It’s not how much of a job AI can automate that matters. It’s which parts.
The insight is this: when automation removes the low-expertise tasks from a job - the routine data gathering, the basic processing, the scheduling - the remaining work concentrates around higher-expertise activities. The job becomes harder, more specialised, and better paid. But fewer people can do it, so employment in that role falls.
When automation removes the high-expertise tasks - the complex analysis, the specialist judgement - the job gets easier. More people can do it. Employment expands, but wages drop.
Autor and Thompson document this empirically across 300+ US occupations over four decades. Their accounting clerk example is instructive: computers eliminated much of routine bookkeeping between 1980 and 2018, yet while employment fell by a third, real wages rose by nearly 40%. The remaining work - reconciliations, exception handling, judgement calls - was harder and more valuable.
Inventory clerks went the other way. Automation removed their most skilled work - technical analysis, compliance checks - leaving basic counting and stocking. The job became easier, wages fell, and employment expanded as more people could now do it.
As Neil Thompson put it: taxi drivers once relied on deep knowledge of local streets as a real differentiator. GPS automated that expertise. The result was a more commoditised service - lower wages, many more drivers.
The same task. The same “automation exposure.” Completely opposite outcomes - for wages, employment, and the kind of space those workers need.
This matters enormously for office space demand, because the task-based models produce a single number per occupation and treat it as if it tells you something about future space requirements. It doesn’t. You need to know the direction of the expertise shift.
If AI removes the grunt work from professional roles - the research, the routine drafting, the data processing - the remaining workforce is smaller, more expert, more senior, better paid, and likely needs better space. Less total square footage, but higher quality. More collaborative, more client-facing, more premium.
If AI removes the high-expertise components and commoditises the role, you get more people doing simpler work for lower pay. The space requirement shifts toward cheaper, more generic, possibly non-office settings. Same occupation. Same AI exposure score on the spreadsheet. Completely different implications for your portfolio.
WE NEED A BIGGER PIE
There’s another variable that every task-based model ignores: growth.
The bottom line is an absolute certainty: AI means we will need fewer people to achieve our current level of output.
The question is whether the pie stays the same size. If an economy grows - new products, new services, expanded demand - then productivity gains get absorbed into expansion rather than headcount reduction. Jevons paradox: when something becomes cheaper and more efficient, demand for it can increase.
But growth doesn’t always bring jobs. Bloomberg recently highlighted an unprecedented “jobless boom” in the US - GDP growing while non-farm payroll growth flatlines. The divergence has never been this persistent this far into an expansion. If AI reinforces that pattern, even economic growth won’t necessarily translate into office demand.
For a low-growth economy like the UK, the arithmetic is harder still. Productivity gains without matching demand growth translate directly into headcount reduction. This macroeconomic context is absent from every task-based model I’ve seen, and it’s arguably the most consequential variable in the system.
HOW TO ACTUALLY THINK ABOUT THIS
So if spreadsheet determinism doesn’t work, what does?
The answer is to stop pretending we can model 10 years of AI-driven change with decimal places and instead be honest about what’s knowable at different time horizons.
Three years out is an engineering problem.
Most relevant variables are already observable. Lease structures are signed. Supply is largely consented. Hybrid patterns have stabilised. AI adoption is still early for most firms.
Three-year demand is a function of things you can measure today: lease expiry profiles, observed attendance rates, sector-level employment trends, and the hiring slowdowns GAISI is already documenting. The methodology should be empirical, not modelled.
Five years is where it gets genuinely hard - but not impossible.
AI capabilities in 2031 will be radically different from today, but organisational adaptation will still be incomplete. Too far for extrapolation, too near for speculation.
The right framework here is not task decomposition. It’s two variables: productivityand growth. How much more productive will AI make your people - actually, not theoretically? And is demand for your output expanding or flat?
These interact. And they produce radically different space outcomes.
Take a company with 500 people currently occupying 60,000 sq ft. Run it through four scenarios over a five-year horizon:
Scenario 1: Low growth, high AI productivity gain Output +10%. Productivity +40%.The toughest scenario for space. Headcount drops to ~390, space requirement to ~47,000 sq ft - a 22% reduction. And per Autor/Thompson, AI has stripped out the routine work, leaving a smaller, more senior team. They don’t just need less space. They need different space - more collaborative, more client-facing. This firm is handing back a floor and upgrading what remains.
Scenario 2: Low growth, low AI productivity gain Output +10%. Productivity +15%.Nothing dramatic. Headcount drifts to ~480, space to ~57,500 sq ft - barely a 4% reduction. The firm absorbs AI gradually, trims a few roles through attrition, renews at roughly the same size. Most organisations today are probably closer to this than they’d like to admit.
Scenario 3: High growth, high AI productivity gain Output doubles (a fast-growing tech or professional services firm, say). Productivity +40%. Jevons paradox in action. Growth absorbs the productivity gain and then some. Headcount rises to ~715, space to ~86,000 sq ft - a 43% expansion. But the type of space changes dramatically: fewer individual desks, more project space, more client-facing environments.
Scenario 4: High growth, low AI productivity gain Output doubles. Productivity +15%.Growth without much AI transformation. Headcount expands to ~870, space surges past 104,000 sq ft. Scaling the old way - more people, more desks. But this may be the least likely scenario over five years, because firms growing this fast tend to invest most aggressively in AI.
The point is not that these numbers are precise - they’re napkin maths. The productivity ranges (15-40%) reflect early-adopter evidence: coding teams reporting 30-50% gains, legal and customer service operations seeing 2-3x throughput. Many firms will be lower, particularly over five years. Over ten - which is more typical of CRE investment horizons - these ranges become conservative. But they show what task-based models fundamentally miss: the same AI productivity gain can mean 22% less space or 43% more space, depending on whether a firm is growing. No occupation-level task score tells you which one you’re in. Only your own strategic context does.
These scenarios assume constant density at 120 sq ft per person. In practice, collaborative space runs larger per head than desk-based processing space - which narrows the reduction in Scenario 1 but reinforces the point about character over quantity.
And the Autor/Thompson expertise lens adds a third variable: what kind of space? In three of four scenarios, routine processing work diminishes and expert, collaborative work grows. The square footage number alone misses this. You might need less space in total but higher specification - or more space of a fundamentally different kind.
NOTE: There are other variables these scenarios don’t capture - attendance patterns, peak-load coordination, the logic of signing a five-day lease for three-day usage, whether co-location becomes more or less important as teams shift to creating and curating AI agents. These are real and consequential. But they are also deeply specific to each organisation’s culture, stage, and ways of working - and largely unknowable over a 5-10 year horizon. They reinforce the point: the answers live inside each company’s particular circumstances, not in a macro model.
Ten years is scenario territory.
Anyone offering a 10-year office demand forecast with specific numbers is selling confidence they don’t have. The honest approach is qualitative scenarios - genuinely different futures. In one, AI delivers transformative productivity and new sectors emerge. In another, productivity gains outstrip demand growth, creating structural surplus in commodity stock. In a third, the Jevons paradox catalyses broader expansion. In a fourth, the US-style jobless boom becomes structural - output growing, employment stagnant.
No spreadsheet helps you choose between these. What helps is understanding the forces, tracking the signals, and building resilience across multiple futures.
THE SUPPLY TRAP
There’s a temptation, particularly for landlords and investors, to look at the current supply picture and take comfort. There is already a well-documented shortage of the kind of space the best occupiers want - high-specification, ESG-compliant, well-located, operationally excellent. In many UK markets, occupiers are being pushed to second-best options because the best simply isn’t available.
But relying on supply constraints to fill your building is increasingly risky. AI doesn’t just change how much space firms need - it makes hybrid and distributed working progressively easier and more effective. As thetools for asynchronous collaboration, AI-synthesised meeting outputs, and rich shared context improve, the compulsion to be in a specific physical space diminishes. The occupier who accepted your second-best building because their first choice was full might, in three years’ time, decide they don’t need a central office of that size at all.
Supply constraints are a short-term tailwind. They are not a strategy.
WANT BEATS NEED
This brings us to what I think is the most important strategic question in office real estate right now - and it has nothing to do with task decomposition models.
The #SpaceAsAService era has already demonstrated that selling to someone who needs your product is fundamentally different from creating something someone actively wants. The entire trajectory of operational intensity in the office sector - the rise of flexible space, managed offices, hospitality-influenced design, amenity-rich environments - reflects this shift. Just building to spec is no longer enough.
AI accelerates this. If the processing, analysis, and document production that currently fill desks get absorbed by AI, the purpose of the office shifts further toward collaboration, client relationships, mentoring, culture-building, and the irreducibly human work that remains. Space that serves those purposes will be wanted regardless of macro demand trends. Space that’s still designed for rows of people doing information processing will not.
For developers and investors, this means every asset decision needs to start with a question that no macro model can answer: when this building is ready, what will companies want from their workspace? Not what will they need - because need is declining. What will they choose? What will they pay a premium for? What will make them pick your building over the increasingly viable alternative of not having an office at all?
You can still win big in a shrinking market if you’re building something people choose rather than something they’re forced to occupy. But it requires understanding what work is becoming - not just how much of it there is.
Relying on aggregate demand to fill your building is a bet on a macro variable you can’t control and increasingly can’t predict. Building something people actively desire is a bet on quality, experience, and understanding the future of work.
That’s a better bet.
CRE: Constraints, Moats and Value
AI is removing the constraints that built CRE’s moats. What replaces them?
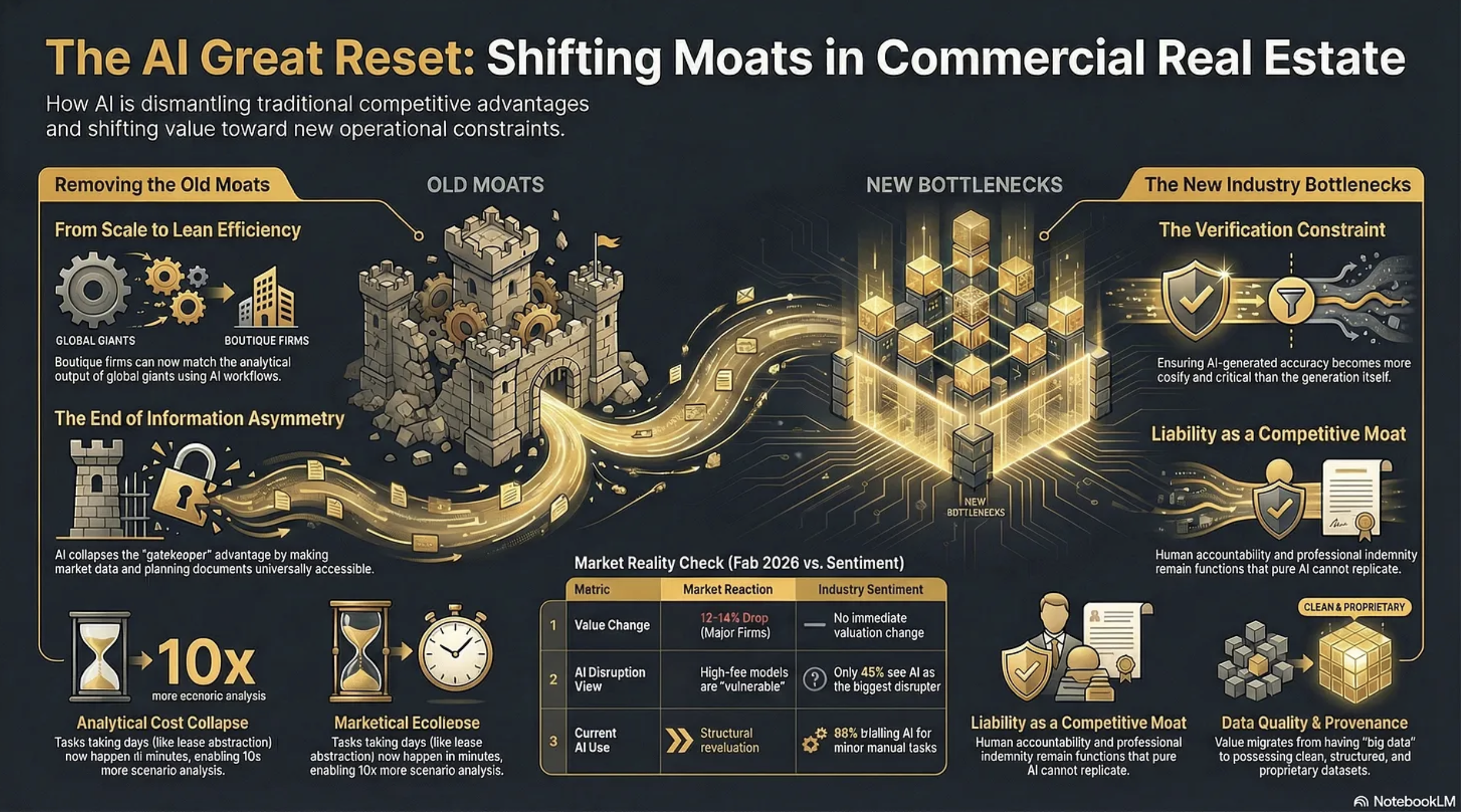
Two rather contradictory things happened on Wednesday, 11th February, 2026. First, shares in CBRE, JLL and Cushman & Wakefield fell precipitously on Wall Street, erasing circa 12-14% of their value. The consensus reason?
“We believe investors are rotating out of high-fee, labor-intensive business models viewed as potentially vulnerable to AI-driven disruption”
And then, on exactly the same day, PropTech giant Yardi put out a research report alongside the Association of Real Estate Funds (AREF) ‘examining how the real estate investment industry is responding to operational pressures through technology, data and digital transformation.’
Matt Glenny, commercial and investment management director at Yardi, describes the findings this way:
“The report gives us a real insight into the perception of the real estate industry compared to a lot of the hype that we hear. Just 45% of respondents see AI as the biggest tech disruptor of the next three to five years”
He adds that…
“88% of respondents are trialling AI in some form to automate or enhance performance of manual tasks such as reading and summarising documents and automating meeting minutes. Predictive analytics and the adoption of AI agents are viewed as future aspirations rather than a current consideration.”
So, the market and the industry are pointing in opposite directions.
Who is right?
Sangeet Paul Choudary, senior fellow at the University of California, Berkeley has written:
“New tech collapses old constraints. Once a constraint disappears, the logic of competitive advantage and business model design must be reimagined from first principles.”
If this is so then we need to look at what constraints AI is removing, what new ones it will impose, and how defensible are the moats underpinning current profitability within the CRE professional services industry.
What follows demonstrates the ‘Release’ phase of our RIRA Framework. Starting with…
CONSTRAINTS AI REMOVES IN CRE
Analytical Cost
Tasks that previously required teams of analysts working for days - lease abstraction, comp analysis, market research, financial modelling, due diligence document review - can now be performed in minutes. This makes existing work cheaper and, perhaps more importantly, it makes previously uneconomic work viable. The “non-consumption” opportunity is real: firms can run 50 scenario analyses where they previously ran 3, or screen 200 properties where they previously screened 20.
Knowledge Access
Information asymmetry - knowing things that clients and competitors don’t - has historically been a core source of CRE value. AI though will collapse this by making market data, comparable transactions, planning documents, and regulatory frameworks accessible to anyone with a well-structured prompt. The gatekeeping function that sustained brokerage margins will erode when the information itself becomes abundant. Proprietary data will exist, and still have considerable value, but far more information will become accessible than many realise.
Coordination
This is perhaps the least appreciated constraint that is being removed by AI. CRE transactions involve coordinating across multiple parties - lawyers, surveyors, lenders, agents, asset managers - each operating within their own systems and timelines. AI can interpret across these disparate data sources without requiring standardisation or consensus, compressing transaction timelines and reducing the friction that historically justified intermediary fees.
Talent Scaling
This is a fundamental constraint that AI is dismantling. A boutique firm with three sharp principals and well-designed AI workflows can now produce analytical output that previously required the likes of CBRE’s headcount. The scale advantage that the big companies enjoyed, hundreds of researchers, analysts, and junior professionals feeding the advisory machine, becomes less decisive when AI handles the analytical infrastructure underneath the senior relationship.
Geographic Knowledge
Deep local market knowledge - planning regimes, tenant dynamics, micro-location factors - has been a genuine moat for regional specialists. AI agents with access to planning portals, EPC data, Land Registry records, and local comparable evidence can approximate (not yet replicate) much of this knowledge, reducing the premium that locality alone commands.
CONSTRAINTS AI INTRODUCES
Verification
This becomes the new bottleneck. The more convincing AI outputs become, the harder hallucinations are to spot, and the greater the temptation to skip verification. This is a genuinely new constraint - the cost of ensuring an AI-generated IC pack is accurate may exceed the cost of generating it. Firms that build robust evidence architecture gain a real advantage; firms that don’t take on hidden liability risk.
Liability and Accountability
These create a structural constraint. When a junior analyst produces a flawed valuation, there’s a clear chain of professional accountability. When an AI system produces one, the liability question is genuinely unresolved. Professional indemnity, regulatory compliance, and fiduciary duty all sit awkwardly with AI-generated outputs.
However, this means that liability can become a moat. In knowledge work with ambiguous outcomes, absorbing liability remains a function that pure AI tools cannot perform.
Data Quality and Provenance
These constraints intensify. AI systems are only as good as their inputs, and CRE data remains fragmented, inconsistent, and often proprietary. The firms that have clean, structured, proprietary datasets gain compounding advantage. Those relying on the same publicly available data as everyone else will find their AI outputs commoditised immediately.
Governance and Workflow Design
These become a constraint on deployment speed. It’s not enough to have capable AI - you need checkpoints, audit trails, escalation protocols, and quality assurance routines. Building this infrastructure requires architectural thinking that most CRE professionals haven’t had to do before. The firms that solve the governance problem will be able to deploy AI at scale; the rest remain stuck in pilot purgatory.
Cognitive Dependency
This risk emerges as a longer-term constraint (though I believe a major one in the making). As professionals offload analytical tasks to AI, the institutional knowledge that informed those tasks atrophies. Junior professionals who never learn to build a model from scratch may lack the judgement to evaluate whether an AI-generated model is sound. Designing workflows and systemic methodologies to counter cognitive dependency will become a major requirement in knowledge businesses. I address this at length in my ‘Cognitive Sovereignty - Use It or Lose It’ article:
WHY CONSTRAINT MAPPING MUST BE WORKFLOW-SPECIFIC
These are generic constraints that are being removed or introduced across the CRE industry. They’re structural features of what AI does to knowledge work.
But the weighting differs enormously, and analysing them in relation to particular workflows is vital.
Consider the contrast between investment capital markets and property management. In capital markets, the information asymmetry constraint has historically been central to value creation, knowing about off-market deals, having proprietary comp data, and understanding institutional investor appetite. AI’s collapse of that constraint is existential to the business model.
In property management, information asymmetry was never the primary value driver: the constraints that matter are physical presence, emergency response capability, tenant relationship management, and regulatory compliance around health and safety. AI removes some PM constraints (reactive maintenance scheduling, compliance tracking, tenant communication at scale) but leaves the physical and relational constraints largely untouched.
Or compare valuation with development advisory. Standardised valuations face near-total constraint removal, AI can assemble comparables, model cash flows, and produce RICS-formatted reports with diminishing human input. Against that, on the new constraint side, there will be a need for professional sign-off and PI liability.
Other areas of the industry will be largely untouched by AI. Development advisory, for example, faces an irreducible constraint in planning committee politics, local authority relationships, and community engagement. The constraint AI does remove for development (planning application analysis, precedent search, viability modelling) is important but secondary to the human-political constraint that gates every project.
Then there’s leasing, where we’re seeing constraint-swaps. In the US, in multi-family, pricing has had constraints removed but that in turn has created a new legal constraint and we’re seeing several companies being sued over the ‘coordination’ of algorithmic pricing. That constraint doesn’t appear in capital markets or valuation work at all. It’s a constraint born from the interaction of AI capability with a specific regulatory environment (which arguably should have been anticipated).
So the constraint map - which constraints dominate, which are secondary, and critically, how they interact - has to be workflow-specific. And the interactions are where the real insight lives. Which is why our RIRA Framework has ‘Release’ as the first ‘R’ - you need to understand the new constraints that are appropriate to your specific workflow, or sector.
What is absolutely clear though is that AI is fundamentally changing the environment in which our businesses operate, and this in turn means that many of the moats we’ve relied on in the past might no longer exist.
THE FALSE MOATS
The Yardi/AREF report, together with Linkedin commentary on the stock price erasure, and pronouncements during earnings calls, make it clear that many in the industry believe CRE has special protection from several ‘moats’ that make it distinctive from other industries, and more defensible against AI.
These need to be addressed:
“Our relationships are our moat.”
Relationships are real, but their defensive value depends heavily on what those relationships enable.
If a client relationship primarily gives access to deal flow and information, AI erodes the information component. The relationship remains valuable, but the fee it commandscompresses because the analytical work underneath it requires less human capital.
The relationship is a moat for the individual, not necessarily for the firm’s margin structure. And crucially: relationships don’t scale, which means they can’t offset margin compression across the broader business.
“Our data is our moat.”
This is half-true, which makes it dangerous. The major companies do have proprietary transaction data, but much of it sits in unstructured formats, inconsistent taxonomies, and siloed systems. Having data and being able to use data as a strategic asset are very different capabilities.
Meanwhile, AI dramatically lowers the cost of assembling comparable datasets from public sources - Land Registry, planning portals, EPC databases, Companies House. The proprietary data advantage is real but narrower than assumed, and it’s a wasting asset if competitors build structured alternatives faster.
“Complex deals require human judgement.”
The definition of “complex” has been a moving target for decades (spreadsheets killed some complexity, databases killed more). What counted as requiring senior judgement five years ago (multi-scenario cash flow analysis, market positioning reports, tenant covenant assessments) is already within AI’s capability.
The residual, true strategic judgement under genuine uncertainty, is real but represents a much smaller slice of billable activity than the industry likes to admit. Is it more than 15%? Most of what brokers call “judgement” involves pattern recognition applied to structured data, which is exactly the capability profile where AI is advancing fastest.
“Regulatory complexity protects us.”
CRE is indeed heavily regulated; RICS standards, planning law, lease code compliance, environmental regulations. But regulation protects the activity, not the incumbent. AI systems that can navigate regulatory requirements more reliably than human professionals don’t erode the regulatory constraint - they erode the premium charged for managing it. Regulation becomes a moat only if firms combine it with liability absorption and governance credibility.
“Our brand and institutional trust are our moat.”
For trophy transactions - the £500m office acquisition, the major corporate relocation - institutional brand matters. Clients want CBRE or JLL on the cover page for their board. But this protects the top 5-10% of transactions by value. For the long tail of mid-market deals, where the analytical quality matters more than the logo, brand becomes less decisive as AI enables smaller firms to produce institutional-grade output.
“Scale is our moat.”
This is the one Wall Street is actively repricing. Scale was a moat when it provided analytical capability that couldn’t be replicated without hundreds of researchers. AI inverts this as it makes scale available to the lean.
It’s not hard to envisage a five-person firm with well-architected AI workflows producing the analytical throughput that required a 40-person team three years ago.
When technology collapses the constraint that justified your architecture, the architecture itself becomes a liability. The big companies’ headcount, which was their competitive advantage, becomes their cost structure problem.
THE MEANING FOR VALUE CREATION
So if AI is removing constraints, and creating new ones, and the industry’s moats are leaking fast, what does this mean for value creation?
The CRE industry is mistaking a stable playing field for a permanent one. Furthermore, it is thinking about how AI will support its existing operating models, rather than thinking about how to fundamentally change the game.
Last week the CEO of one of the major players said on an earnings call:
“that AI would benefit the business over the longer term, adding that its transaction and investment work would be “most protected” from disruption.”
Which encapsulates this thinking precisely.
The share price crash is the market, brutally and without nuance, beginning to price a structural revaluation into this sector. What the industry now needs to do is double down on understanding where value is migrating to. As analytical and transactional work commoditises, value will migrate to whoever resolves the new constraints - verification, liability, governance, and coordination.
Exactly what this means in terms of products and services is still to be determined. But by diving deep into the first ‘R’ in the RIRA framework, the map starts to become more like the territory, allowing us to better agree with or dismiss most of the ‘noise’ around CRE and AI today.
What is clear is that we have to think harder about where AI is taking us, and explain this precisely to the markets. The competitive advantage will accrue to those who can demonstrate why AI is a feature, not a bug. How many will manage that?
OVER TO YOU
What to do about all of this? What’s the strategic question you should be asking that you’re currently not?